
Introduction
Recently I was asked this question (paraphrasing):
I have a small image dataset that I want to train on Google Colab and its free TPU. Is there a way to do that without having to upload the dataset as TFRecord files to Cloud Storage?
First of all, if your dataset is small, I’d say training on GPU wouldn’t be much slower than on TPU. But they were adamant that they wanted to see how fast training on TPU can be. That’s fine, and the answer is yes. There is a way to do that.
The reason why you need to use TFRecord and Cloud Storage is that unlike GPU, TPU is connected to your VM via an internal network, and TensorFlow has not implemented a way for the TPU to read from your local disk. It only supports reading TFRecord files from Cloud Storage.
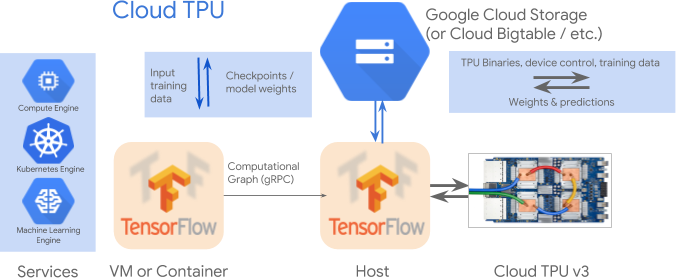
There’s one exception — if your dataset is small enough to fit into memory, TensorFlow can send your entire dataset over the network to the TPU Host, and you can avoid TFRecord and Cloud Storage.
The Solution
Here’s how to do it. I’ll convert this Colab notebook that trains an image classification model using TFRecord files into two notebooks. The first one downloads a subset of the TFRecords files from Cloud Storage and converts them into Numpy arrays. The second one loads the Numpy arrays and train them on TPU.
(You don’t have to read from TFRecords or use the tf.data API in the first notebook. You can read raw image files using PIL or OpenCV and convert them into Numpy arrays as well. Anything that converts the dataset into Numpy arrays will do.)
First Part
We use the first 4 TFRecord files as the training dataset and the last 2 as validation dataset. This translate to 920 images in the training, and 450 images in the validation.
gcs_pattern = 'gs://flowers-public/tfrecords-jpeg-331x331/*.tfrec'
validation_split = 0.19
filenames = tf.io.gfile.glob(gcs_pattern)
train_fns = filenames[:4]
valid_fns = filenames[-2:]
The parse_tfrecord function is taken directly from the original notebook. The raw jpeg files were serialized into the TFRecord files. We need to decode them using tf.image.decode_jepg to get the actual image array.
def parse_tfrecord(example):
features = {
"image": tf.io.FixedLenFeature([], tf.string), # tf.string means bytestring
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar
"one_hot_class": tf.io.VarLenFeature(tf.float32),
}
example = tf.io.parse_single_example(example, features)
decoded = tf.image.decode_jpeg(example['image'], channels=3)
normalized = tf.cast(decoded, tf.float32) / 255.0 # convert each 0-255 value to floats in [0, 1] range
image_tensor = tf.reshape(normalized, [*IMAGE_SIZE, 3])
one_hot_class = tf.reshape(tf.sparse.to_dense(example['one_hot_class']), [5])
return image_tensor, one_hot_class
Now we use the .numpy() method to convert the tensors generated from the tf.data.TFRecordDataset into Numpy arrays, stack the arrays and dump the results to a mounted Google Drive folder.
tf_dataset = tf.data.TFRecordDataset(train_fns).map(parse_tfrecord)
buffer_input, buffer_class = [], []
for tmp_input, tmp_class in tf_dataset:
buffer_input.append(tmp_input.numpy())
buffer_class.append(tmp_class.numpy())
joblib.dump([np.stack(buffer_input), np.stack(buffer_class)], "/gdrive/My Drive/tmp/train.jbl")
Do the same things for the validation dataset and we’re good to go!
Second Part
Now we remove the TFRecord-related parts in the first notebook, load the Numpy arrays from Google Drive, and use tf.data.Dataset.from_tensor_slices API to create a Dataset instance.
arr_input, arr_target = joblib.load("/gdrive/My Drive/tmp/train.jbl")
tensor_input = tf.convert_to_tensor(arr_input)
tensor_target = tf.convert_to_tensor(arr_target)
print(tensor_input.shape, tensor_target.shape)
training_dataset = tf.data.Dataset.from_tensor_slices((tensor_input, tensor_target)).repeat().shuffle(2048).batch(batch_size)
train_steps = tensor_input.shape[0] // batch_size
print("TRAINING IMAGES: ", tensor_input.shape[0], ", STEPS PER EPOCH: ", train_steps)
Do the same to the validation set, and the model should be able to train!
Where’s the Limit?
I created these demonstrative notebooks with very low resource requirements. I’m not sure how the in-memory Dataset instance is stored on the TPU host, so I don’t know how many images you can practically use without getting an OOM from the TPU (they’ll need to fit in the memory of your VM first, of course). I’ll leave it to the readers to try and find out.