
Photo by Josh Gordon on Unsplash
The new Tensorflow 2.0 is going to standardize on Keras as its High-level API. The existing Keras API will mostly remain the same, while Tensorflow features like eager execution, distributed training and other deeper Tensorflow integration will be added or improved. I think it’s a good time to revisit Keras as someone who had switched to use PyTorch most of the time.
I wrote an article benchmarking the TPU on Google Colab with the Fashion-MNIST dataset when Colab just started to provide TPU runtime. This time I’ll use a larger dataset (CIFAR-10) and an external image augmentation library [albumentation](https://github.com/albu/albumentations)s.
It turns out that implementing a custom image augmentation pipeline is fairly easy in the newer Keras. We could give up some flexibility in PyTorch in exchange of the speed up brought by TPU, which is not yet supported by PyTorch yet.
Source Code
-
GPU version (with a Tensorboard interface powered by
ngrok)
The notebooks are largely based on the work by Jannik Zürn described in this post: Using a TPU in Google Colab.
I updated the model architecture from the official Keras example and modified some of the data preparation code.
Custom Augmentation using the Sequence API
From the Keras documentation:
Sequenceare a safer way to do multiprocessing. This structure guarantees that the network will only train once on each sample per epoch which is not the case with generators.
Most Keras tutorials use the ImageDataGenerator class to generate batch and do image augmentation. But it doesn’t leave much room for customization (unless you spend some time reading the source code and extend the class) and the augmentation toolbox might not be comprehensive or fast enough for you.
Class Definition
Fortunately, there’s a Sequence class (keras.utils.Sequence) in Keras that is very similar to Dataset class in PyTorch (although Keras doesn’t seem to have its own DataLoader). We can construct our own data augmentation pipeline like this:
Note the one major difference between Sequence and Dataset is that Sequence returns an entire batch, while Dataset returns a single entry.
In this example, the data has already been read in as numpy arrays. For larger datasets, you can store paths to the image files and labels in the file system in the class constructor, and read the images dynamically in the __getitem__ method via one of the two methods:
-
OpenCV:
cv2.cvtColor(cv2.imread(filepath), cv2.COLOR_RGB2BGR) -
PIL:
np.array(Image.open(filepath))
Reference: An example pipeline that uses torchvision.
Albumentations
Now we use albumentations to define a set of augmentations to be applied randomly to training set and a (deterministic) set for the test and validation sets:
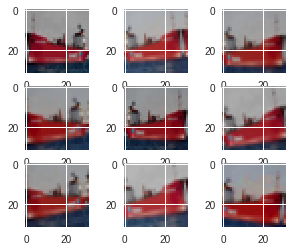
Augmented Samples
ToFloat(max_value=255) transforms the array from [0, 255] range to [0, 1] range. If you are tuning a pretrained model, you’ll want to use Normalize to set mean and std.
Training and Validating
Just pass the sequence instances to the fit_generator method of an initialized model, Keras will do the rest for you:
By default Keras will shuffle the batches after one epoch. You can also choose to shuffle the entire dataset instead by implementing a on_epoch_end method in your Sequence class. You can also use this method to do other dynamic transformations to the dataset between epochs (as long as the __len__ stay the same, I assume).
That’s it. You now have a working customized image augmentation pipeline.
TPU on Google Colab

Model used: Resnet101 v2 in the official example
Notes to the table:
-
The sets of augmentations used by GPU and TPU notebook are slightly different. The GPU one includes a
CLAHEop while the TPU one does not. This is due to an oversight on my part. -
The GTX 1080 Ti results are taken from the official example.
The batch size used by Colab TPU is increased to utilize the significantly larger memory size (64GB) and TPU cores (8). Each core will received 1/8 of the batch.
Converting Keras Models to use TPU
Like before, one single command is enough to do the conversion:
But because the training pipeline is more complicated than the Fashion-MNIST one, I encountered a few obstacles, and had to find ways to circumvent them:
-
The runtime randomly hangs or crashes when I turn on
multiprocessing=Trueinfit_generatormethod, despite the fact thatSequenceinstances should support multiprocessing. -
The TPU backend crashes when Keras has finished first epoch of training and starts to run validation.
-
No good way to schedule training rate. The TPU model only supports
tf.trainoptimizers, but on the other hand the Keras learning rate schedulers only support Keras optimizers. -
The model gets compiled four times (two when training, two when validating) at the beginning of
fit_generatorcall, and the compile time is fairly long and unstable (high variance between runs).
The corresponding solutions:
-
Use
multiprocessing=False. This one is obvious. -
Run a “warmup” round of one epoch without validation data seems to solve the problem.
-
The Tensorflow 2.0 version of Keras optimizer seems to work with TPU models. But as we’re using the pre-installed Tensorflow 1.13.1 on Colab, one hacky solution is to sync the TPU model to CPU and recompile the model using an optimizer with a lower learning rate. This is not ideal, of course. We’d waste 5 ~ 20 minutes syncing and recompiling the model.
-
This one unfortunately I couldn’t find good way to avoid it. The reason why the model get compiled four times is because the last batch has a different size from the previous ones. We could reduce the number to three if we just drop the last batch in training (I couldn’t find a way to do that properly in Keras). Or reduce the number to two if we pick a batch size that is a divisor to the size of the dataset, which is not always possible or efficient. You could just throw away some data to make things easier if your dataset is large enough.
Summary
The TPU (TPUv2 on Google Colab) greatly reduces the time needed to train an adequate model, albeit its overhead. But get ready to deal with unexpected problems since everything is really still experimental. It was really frustrating for me when the TPU backend kept crashing for no obvious reason.
The set of augmentations used here is relatively mild. There are a lot more options in the albumentations library (e.g. Cutout) for you to try.
If you found TPU working great for you, the current pricing of TPU is quite affordable for a few hours of training (Regular \$4.5 per hour and preemptible \$1.35 per hour). (I’m not affiliated with Google.)
In the future I’ll probably try to update the notebooks to Tensorflow 2.0 alpha or the later RC and report back anything interesting.