
Overview
Motivation
Transformer models[1] have been taking over the NLP field since the advent of BERT[2]. However, the high numbers of parameters and the quadratically scaled self attention that is expensive both in computation and memory[3] make the modern transformer models barely fit into a single consumer-grade GPU. Efforts have been made to alleviate this problem[3][4][5], but they are still far from ideal:
- No public models that are pre-trained on BERT-scale corpus (at the time of writing). [3]
- The complexity of the public models is no smaller than the existing transformer models. [4]
- They are just smaller versions of BERT. The self attention is still quadratically scaled. [5]
To make the inference possible on weaker machines, one of the more ideal solutions is to distill the knowledge of a fine-tuned transformer model into a much simpler model, e.g., an LSTM model. Is it possible? Tang et al.[6] shows that they can improve the BiLSTM baseline by distillation and some data augmentation. Although their accuracies are still lagging behind ones of the transformer models, it is still a promising direction.
![Model size and inference speed comparision from Tang et al.[6]](tang-table-2.png)
Model size and inference speed comparision from Tang et al.[6]
In Tang et al.[6], they state the reasons for using data augmentation as:
In the distillation approach, a small dataset may not suffice for the teacher model to fully express its knowledge[7]. Therefore, we augment the training set with a large, unlabeled dataset, with pseudo-labels provided by the teacher, to aid in effective knowledge distillation.
Their single-layer BiLSTM is relatively simple. I wondered if I can do better with more sophisticated without using data augmentation, which is quite complicated in NLP. (Spoiler — I failed.)
Experiment Setup
- SST-2 from the GLUE benchmark is used as the downstream task (binary classification).
- Because the test set of SST-2 does not come with labels, I create my own test set from the dev set using a f50/50 random split.
- A BERT-base-uncased model is finetuned on the training set. The final model is picked via the dev set.
- The predicted logits of the training set from the BERT model are recorded and stored in a file.
- An LSTM/GRU model is created and trained on the logits using an MSE objective as in [6]. There are several deviations from [6]:
- It shares the tokenizer with the BERT model, i.e, they see exactly the same input sequences.
- The embedding matrix of the fine-tuned BERT model is copied into the LSTM/GRU model and frozen during training (not updated). The vocabulary size of BERT is too large for SST-2 to be fine-tuned (empirically gets lower accuracies).
- It uses two to four layers of LSTM/GRU units with input, layer-to-layer, embedding, weight/variational dropouts.
- It uses an attention layer slightly modified from DeepMoji[8].
- A baseline LSTM/GRU model is created using the same hyper-parameters and trained on the labels using a cross-entropy objective.
- It copies and freezes the embedding matrix of BERT the fine-tuned BERT model as in the last step.
Experiment Results
- The baseline and the distill models were getting basically the same accuracy (86%~89% dev and 84%~87% test comparing to 92% dev and 94% test of BERT).
- The distill version was more likely to get marginally better accuracies, but they are almost indistinguishable in practice.
- The accuracies were very sensitive to hyper-parameters.
- The LSTM model is 1 / 3 the size of the BERT model but trains almost 8 times faster.
Analysis
One of the reasons behind the lack of improvement from distillation is probably the BERT softmax distribution on the training set:
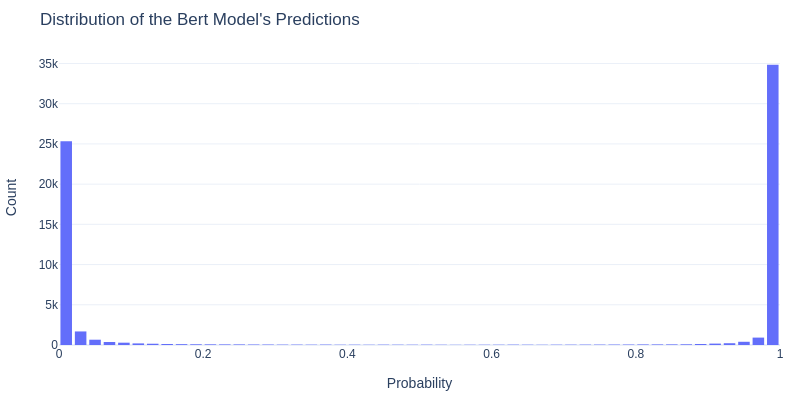
The BERT model is too confident in its prediction, so the logits do not provide much more information than the labels. Training on the softmax output directly and tuning the temperature[9] might be helpful, but has not yet been experimented.
Implementation Details
The source code and the notebooks used in this post is published on Github.
- I recycled the RNN code from one of my old projects modern_chinese_nlp (which was heavily inspired by fast.ai) and modernized it to be compatible with PyTorch 1.5.
- Models were trained using my high-level PyTorch wrapper library pytorch-helper-bot. Please install this specific version (latest at the time of writing) if you want to reproduce the result.
- huggingface/nlp was used to load the SST-2 dataset.
- The BERT-base-uncased model was loaded using huggingface/transformers.
References
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. Attention Is All You Need.
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- Kitaev, N., Kaiser, Ł., & Levskaya, A. (2020). Reformer: The Efficient Transformer.
- Beltagy, I., Peters, M. E., & Cohan, A. (2020). Longformer: The Long-Document Transformer.
- Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.
- Tang, R., Lu, Y., Liu, L., Mou, L., Vechtomova, O., & Lin, J. (2019). Distilling Task-Specific Knowledge from BERT into Simple Neural Networks.
- Ba, L. J., & Caruana, R. (2014). Do Deep Nets Really Need to be Deep?
- Felbo, Bjarke and Mislove, Alan and Sogaard, Anders and Rahwan, Iyad and Lehmann, Sune (2017) Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm
- Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network.