
Preamble
Jigsaw hosted a toxic comment classification competition[2] in 2018, and has also created an API service for detecting toxic comments[3]. However, it has been shown that the model trained on this kind of datasets tend to have some biases against minority groups. For example, a simple sentence “I am a black woman” would be classified as toxic, and also more toxic than the sentence “I am a woman"[4]. This year’s Jigsaw Unintended Bias in Toxicity Classification competition[1] introduces an innovative metric that aims to reduce such biases and challenges Kagglers to find out the best score we can get under this year’s new dataset.
Unsurprisingly, fine-tuned BERT models[6] dominate the leaderboard and are reported as the best single model in top solutions. People get better scores by using custom loss weights, negative sampling techniques, and ensembling BERT with different kinds of (weaker, e.g. LSTM-based) models with ensemble schemes more appropriate with this metric. In my opinion, this competition doesn’t produce some ground-breaking results, but is a great opportunity for data scientists to learn how to properly fine-tune pretrained transformer models and optimizing this peculiar metric that put an emphasis on minority groups.
XLNet[7] was published and its pretrained model released in the final week of the competition. Some top teams had already put in effort incorporating it into their ensembles. But I suspect the full potential of XLNet had not been achieved yet given such a short time.
My Experience
I entered this competition with two weeks left. I built a pipeline that I am rather happy with and made some good progress at the start. Unfortunately, the metric function I copied from a public Kaggle Kernel was bugged (an important threshold condition >= 0.5 was replaced by > 0.5), which severely undermines my effort in the last week because I was optimizing the wrong thing, and it caused the local cross-validation score to deviate from the public leaderboard score. In the end, I was placed at 187th on the private leaderboard. I used only Kaggle Kernel and Google Colab to train my models.
After the competition, I spent some time debugging my code and finally found the bug. I published the corrected solution on the on Github at ceshine/jigsaw-toxic-2019. It should be able to get into silver medal range by ensembling 5 to 10 models. I tried incorporating the loss weighting used in 6th place solution[11] and the “power 3.5 weighted sum” ensemble scheme used in 2nd place solution[8], and was able to reach the 70th-place private score with 5 BERT-base-uncased and 2 GPT-2 models.
I think the performance of my single models can still be slightly improved, but the rest of the gains needed to reach gold medal range probably can only be achieved by creating a larger and more diverse ensemble. (Hopefully, I’ll manage to find time to get back to this in the future.)
Bias Reduction
So did the metric really reduced unintended bias? The following is a sample of cross-validation metric scores from a single BERT-base-uncased model:
- Overall AUC: 0.972637
- Mean BNSP AUC: 0.965623 (background-negative subgroup-positive)
- Mean BPSN AUC: 0.928757 (background-positive subgroup-negative)
- Mean Subgroup AUC: 0.906707
However, these scores only show that the model is much better than a model that take random guesses. We need a human-level score baseline or the score from models trained using only overall AUC to have a proper comparison.
Qualitative Research
One way to quickly find if the model still contains severe bias against minority groups is to do some quick qualitative checks. This is what we have previously, before the new metric:
This tweet is no longer available.
(I think the above results were taken from the Perspective API[3]. The model used by the API appears to have been changed as the predicted toxicity are different now.)
Here’s what we have now (the numbers are in percentage(%)):
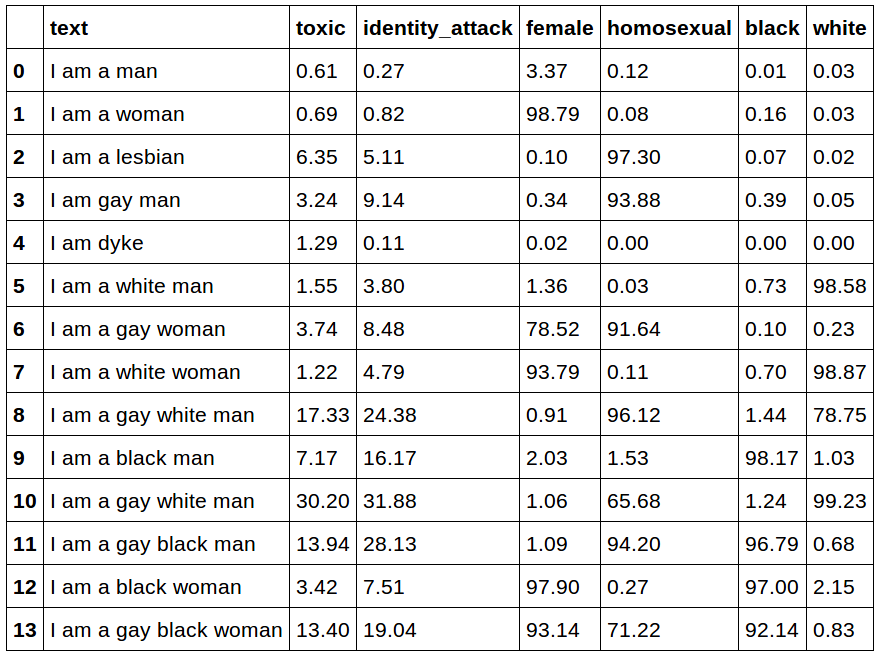
Results from a fine-tuned BERT-base-uncased model
Not bad! Only “I am a gay white man” has a toxicity probability larger than 20%. The new metric at least managed to eliminate these severe biases that look ridiculous to most human beings.
A few more examples from the actual (validation) dataset:
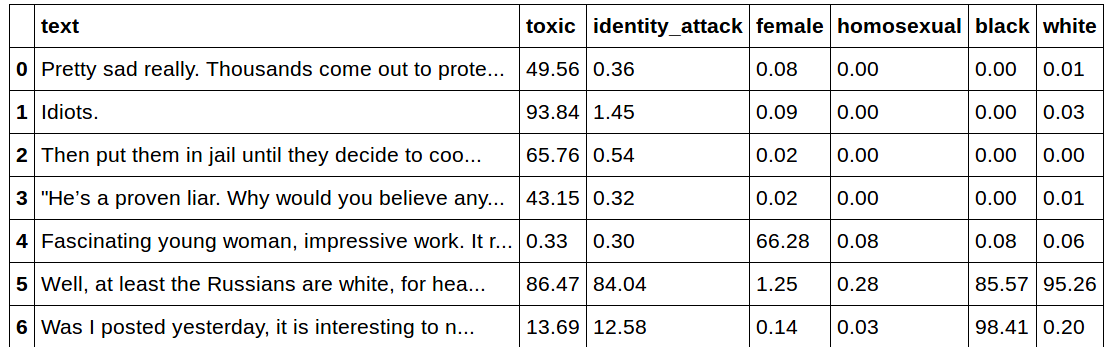
Results from a fine-tuned BERT-base-uncased model
It shows that the model can correctly identify subgroups in more complicated sentences.
Summary of Top Solutions
Currently only covers 2nd, 3rd, and 4th place solutions.
- Loss Weighting:
- Simply count the number of appearances of an example in the four AUC scores that constitute the final metric score. [8]
- Increase the weight of positive examples. [9]
- Target weight multiplied by log(toxicity_annotator_count + 2). [9]
- Blending:
- “Power 3.5 weighted sum”[16], take
prob ** 3.5of the predicted probability before calculating the weighted sum/average when ensembling. [8] - Use optuna to decide blending weights. [9]
- “Power 3.5 weighted sum”[16], take
- Target variables:
- Discretize the target variable (via binning). [8]
- Use identity columns as auxiliary targets. [8]
- Use fine-grain toxicity columns as auxiliary targets. [10]
- Mixing primary and auxiliary targets when making final predictions. (e.g.
toxicity_prediction - 0.05 * identity_attack_prediction) [10]
- BERT language model fine-tuning. Some reported it successful[8][10], while some didn’t[9]. It is resource-intensive and takes a lot of times to train. (I had also tried it myself with a subset of the training dataset, but did not get better downstream models.)
- [8] also changed the segment_id when fine-tuning via
segment_ids = [1]*len(tokens) + padding. (Not sure why.)
- [8] also changed the segment_id when fine-tuning via
- Negative downsampling: cut 50% negative samples (in which target and auxiliary variables are all zero) after the first epoch. [9]
- Head + tail sequence truncation[17]. [9]
- Further fine-tuning with old toxic competition data. [9]
- CNN-based classifier head for GPT-2 models. [10]
- Pseudo-labeling for BERT: didn’t work[9].
- Data augmentation: didn’t work[9].
- Prediction value shift of each subgroup to optimize BPSN & BNSP AUC: didn’t work[9].
References
- Jigsaw Unintended Bias in Toxicity Classification
- Toxic Comment Classification Challenge
- Perspective: What if technology could help improve conversations online?
- Reported biased results (on Twitter)
- Borkan, D., Dixon, L., Sorensen, J., Thain, N., & Vasserman, L. (2019). Nuanced Metrics for Measuring Unintended Bias with Real Data for Text Classification.
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R., & Le, Q. V. (2019). XLNet: Generalized Autoregressive Pretraining for Language Understanding.
- [2nd place] solution
- [3rd place] solution
- [4th place] COMBAT WOMBAT solution
- [6th place] Kernel For Training Bert (The real stuff)
- [7th place] solution
- [9th place] solution
- [14th place] solution
- [23rd place]A Loss function for the Jigsaw competition
- Reaching the depths of (power/geometric) ensembling when targeting the AUC metric
- Sun, C., Qiu, X., Xu, Y., & Huang, X. (2019). How to Fine-Tune BERT for Text Classification?