
The Google AI Blog post
This post on Google AI Blog explains the premise, background, and related works of this paper pretty well. I’m not going to repeat them in this post. Instead, I’ll try to fill in some of the gaps I see as someone that is familiar with this topic but does not follow very closely with the latest development.
Firstly, I want to point out something in the Google AI post that confuses me. In the first paragraph the authors stated:
While these existing multilingual approaches yield good overall performance across a number of languages, they often underperform on high-resource languages compared to dedicated bilingual models, which can leverage approaches like translation ranking tasks with translation pairs as training data to obtain more closely aligned representations. [emphasis mine]
But in the result table, we don’t see any improvement over LASER[2] in the 14 high-resource language group:
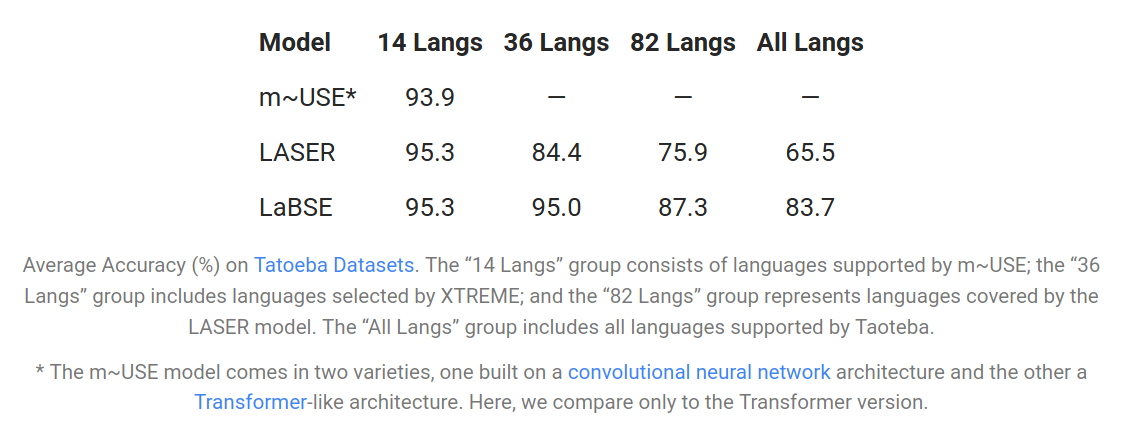
Maybe they just want to mention a general characteristic of multilingual approaches. Nonetheless, the improvements in the low resource languages are significant and might be attributed to the fine-tuning task, the improved capacity of the model (LASER uses at most 5 Bi-LSTM layers), or the larger pre-train dataset.
The LaBSE Model
Datasets
The monolingual data was collected from CommonCrawl and Wikipedia.
The translation corpus is constructed from the web pages using a bitext mining system similar to the approach described in Uszkoreit et al. (2010).
Pretraining task
MLM(masked language model) and TLM(translation language modeling) are very common in recent NLP research. In case you forgot the details (like I did with the TLM):
![source[3]](mlm_tlm.png)
source[3]
Basically, TLM is to throw in a pair of parallel sentences, randomly mask some tokens, and hope that the model will use information in its counterpart sentence to fill in the correct token.
Getting sentence embeddings
Sentence embeddings are extracted from the last hidden state of the encoder [CLS] token.[1] This is in contrast with the pooling methods used in Sentence-BERT[4]:
![source[4]](sbert.png)
source[4]
I did not see any similar ablation study in [1] and its predecessor [5]. Maybe this is something that can be tuned to further improve accuracy.
Fine-tuning task
(As the Google AI Blog describes, the fine-tuning task is the translation ranking task. The objective is to find the true translation over a collection of sentences in the target language.)
![source[1]](dual-encoder.png)
source[1]
The paper used bidirectional dual encoders with additive margin softmax loss with in-batch negative sampling:
![source[1]](formula-1.png)
source[1]
The paper used $\phi(x, y) = cosine(x, y)$ as the embedding space similarity function. A margin $m$ is used on the ground-truth pair to improve separation between translations and non-translations[5]:
![source[5]](margin.png)
source[5]
Because the translation is bi-directional, the loss is averaged over the two directions:
Note that the negative sampling is in-batch(i.e. taken from within the batch), so a large batch size is required as in contrastive learning of visual representations[6]. The paper introduced Cross-Accelerator Negative Sampling to do negative sampling across distributed accelerators:
![source[1]](sampling.png)
source[1]
This constraint implies that you will likely not able to get good performance training on only one GPU or even one TPU device.
Additional Analysis
BUCC and UN task
![source[1]](bucc.png)
source[1]
![source[1]](un-task.png)
source[1]
The LaBSE outperforms bilingual models on the BUCC mining task and the UN parallel sentence retrieval task. Maybe this is the confusing statement of the Google AI Blog post is about.
Initialize Weights from Multilingual BERT
This approach is to initialize weights from the multilingual BERT model and then fine-tune as bidirectional dual encoders like before. The resulting model will perform well on high resource languages but poorly on low resource ones.
Our pre-training approach improves over multilingual BERT on tail languages due to a combination of reasons. We use a much larger vocab , 500k versus 30K, which has been shown to improve multilingual performance (Conneau et al., 2019). We also include TLM in addition to MLM as this has been shown to improve cross-lingual transfer (Conneau and Lample, 2019). Finally, we pretrain on common crawl which is much larger, albeit noisier, than the wiki data multilingual BERT is trained on. [emphasis mine]
Using the Pre-trained Model
Because of the batch size constraint, we probably won’t be able to train the model from scratch or even further fine-tune on the dual encoder task without a large distributed training environment. In most cases, we’d directly use the pre-trained model released by the paper authors, which is available on TF Hub with code examples: LaBSE.
I’d love to see the model get ported to the huggingface/transformers package, which is pretty much the standard package for transformer models nowadays. It’ll make it easier to fine-tune the model on other tasks.
Here’s my thought on how to port the weights: There’s already a script exported weights from TF SavedModel to TF checkpoint. The next step should be to load the checkpoint in huggingface/transformers. Then you can save the weights using the huggingface/transformers API so it can be used by both TensorFlow and PyTorch.
Currently, I don’t need this kind of fine-tuning. So I’ll wait for someone else to do the porting.
References
- Feng, F., Yang, Y., Cer, D., Arivazhagan, N., & Wang, W. (2020). Language-agnostic BERT Sentence Embedding.
- Mikel Artetxe and Holger Schwenk. 2019b. Massively multilingual sentence embeddings for zero-shot cross-lingual transfer and beyond. Trans. Assoc. Comput. Linguistics, 7:597–610.
- Lample, G., & Conneau, A. (2019). Cross-lingual Language Model Pretraining.
- Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks.
- Yang, Y., Abrego, G. H., Yuan, S., Guo, M., Shen, Q., Cer, D., … Kurzweil, R. (2019). Improving multilingual sentence embedding using bi-directional dual encoder with additive margin softmax. IJCAI International Joint Conference on Artificial Intelligence, 2019-August, 5370–5378.
- Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2019). A Simple Framework for Contrastive Learning of Visual Representations.