
Update on 2020-08-22: using torch.cuda.max_memory_allocated() and torch.cuda.reset_peak_memory_stats() in the newer version (1.6+) of PyTorch is probably more accurate. (reference)
Motivation
Recently I’ve been trying out EfficientNet models implemented in PyTorch. I’ve managed to successfully fine-tune pretrained EfficientNet models on my data set and reach accuracy on par with the mainstream ones like SE-ResNeXt-50. However, training the model from scratch has proven to be much harder.
Fine-tuned EfficientNet models can reach the same accuracy with much smaller number of parameters, but they seem to occupy a lot of GPU memory than it probably should (comparing to the mainstream ones). There is an open issue on the Github Repository about this problem — [lukemelas/EfficientNet-PyTorch] Memory Issues.
Github user @selina suggested that the batch normalization and Swish activation are the bottlenecks, and claming that by using custom ops in PyTorch, we can reduce GPU memory usage by up to 30%.
Custom Swish Function
This is the most straightforward implementation of a Swish activation module used in EfficientNet ($f(x) = x \cdot \sigma(\beta x)$ with $\beta = 1$):
The gradients of this module are handled automatically by PyTorch.
This is the Swish activation module implemented using custom ops:
Here we handle the gradients explicitly. We keep a copy of the input tensor and use it in back-propagation stage to calculate the gradients.
Does this latter version really significantly reduce the GPU memory footprint? — This is the question we want to answer in the following section.
Profiling CUDA Memory Usage
I’ve just learned that now PyTorch has a handy function torch.cuda.memory_allocated() that can be used to profile GPU memory usage:
Returns the current GPU memory occupied by tensors in bytes for a given device.
Note: This is likely less than the amount shown in nvidia-smi since some unused memory can be held by the caching allocator and some context needs to be created on GPU. See Memory management for more details about GPU memory management.
I used to extract that information from calls to nvidia-smi command, but the number reported by nvidia-smi will be very inaccurate due to the PyTorch memory caching mechanism.
A simple fully-connected neural network was created to be tested against:
We simply inserted torch.cuda.memory_allocated() between model training statements to measure GPU memory usage. For more sophisticated profiling, you should check out something like pytorch-memlab.
Observations
When using batch sizes of 128, the GPU memory footprints of the training loop were:
(1st step)
data: 524 MB
forw: 1552 MB
loss: 1552 MB
back: 1044 MB
step: 1044 MB
====================
(2nd step)
data: 1044 MB
forw: 2072 MB
loss: 2072 MB
back: 1044 MB
step: 1044 MB
(The latter steps are exactly the same as the second one.)
The difference between the first and the latter steps is probably due to gradients not being allocated until loss.backward() is called.
The peak memory usage happens right after the forward-propagation. As has been shown in the custom-op implementation of Swish, some function requires PyTorch to save some forms of the input tensors to be able to back-propagate. Those saved information are discarded after the backward phase. By this logic, we can guess that training with larger batch sizes will use more memory, and this intuition is confirmed by experiments:
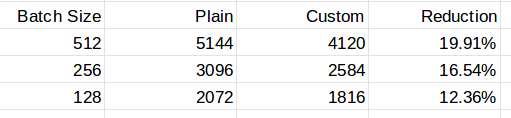
Peak Memory Usage
The custom-op version of Swish uses almost 20% less memory when batch size is 512. PyTorch augograd probably decides to save more information in the forward phase to avoid some re-calculation in the backward phase. Note that in the custom-op version, i * (1 - sigmoid_i) in the backward function can be refactored to reuse the calculated number i * torch.sigmoid(i) in the forward function.
The custom-op version might have traded some speed for memory. I have not done any profiling on time yet. But as the bottleneck in my system is often the GPU memory, I’d happily accept the tradeoff anyway.
Source Code
My fork of EfficientNet-PyTorch has replaced the original swish function with the more memory-efficient one.
The notebook used to run the experiments: