
Preamble
“Training Question Answering Models From Synthetic Data” is an NLP paper from Nvidia that I found very interesting. Question and answer(QA) data is expansive to obtain. If we can use the data we have to generate more data, that will be a huge time saver and create a lot of new possibilities. This paper shows some promising results in this direction.
Some caveats:
- We need big models to be able to get decent results. (The paper reported question generation models with the number of parameters from 117M to 8.3B. See the ablation study in the following sections.)
- Generated QA data is still not at the same level as the real data. (At least 3x+ more synthetic data is needed to reach the same level of accuracy.)
There are a lot of contents in this paper, and it can be a bit overwhelming. I wrote down parts of the paper that I think is most relevant in this post, and hopefully, it can be helpful to you as well.
Method
Components
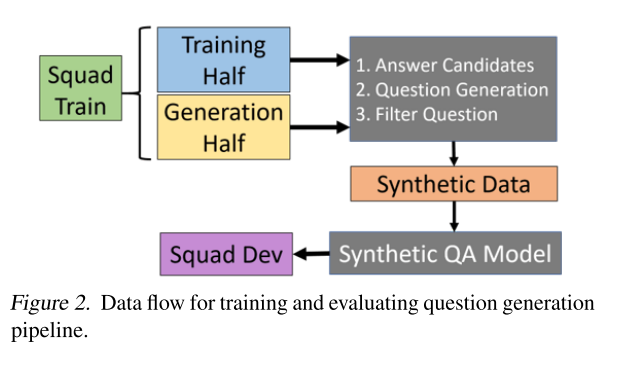
There are three or four stages in the data generation process. Each stage requires a separate model:
- Stage 0 - [Optional] Context generation: The SQuAD 1.1 training data were used to train the following three stages (Figure 2 below). But when testing/generating, we can choose to use real Wikipedia data or use a model to generate Wikipedia-like data.
- Stage 1 - Answer Generation ($\hat{p} \sim p(a|c)$): A BERT-style model to do answer extraction from the given context. The start and the end of the token span are jointly sampled.
- Stage 2 - Question Generation ($\hat{q} \sim p(q|\hat{a},c)$): Fine-tuned GPT-2 model to generation question from the context and the answer.
- Stage 3 - Roundtrip Filtration ($\hat{a} \stackrel{?}{=} a^{\ast} \sim p(a|c,\hat{q})$): A trained extractive QA model to get the answer from the context and the generated question. If the predicted answer matches the generated answer, we keep this triplet (context, answer, and question). Otherwise, the triplet is discarded.
The last step seems to be very strict. Any deviation from the generated answer will not be tolerated. However, given the EM(exact match) of the model trained on SQuAD 1.1 alone is already 87.7%, it’s reasonable to expect that the quality of answer predicted by the filtration model to be quite accurate. The paper also proposes an over-generation technique (generate two questions for each answer and context pair) to compensate for those valid triplets being discarded.
(Taken from the source paper)
More Details
Context Generation
Beside using Wikipedia documents as contexts, this paper also generates completely synthetic contexts using an 8.3B GPT-2 model:
This model was first trained with the Megatron-LM codebase for 400k iterations before being fine-tuned on only Wikipedia documents for 2k iterations. This allows us to generate high-quality text from a distribution similar to Wikipedia by using top-p (p = 0.96) nucleus sampling.
Answer Generation
This paper train the answer generation model to match the exact answer in the training data. This naturally ignores the other possible answers from the context but seems to be a more generalizable way to do it.
The joint modeling of the starts and the ends of the answer span, which is reported to perform better, creates more candidates in the denominator in the calculation of the likelihood.
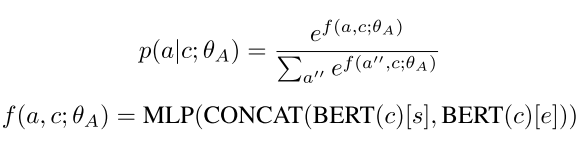
(Taken from the source paper)
(I’m not very sure about the complexity and performance impact of this joint approach.)
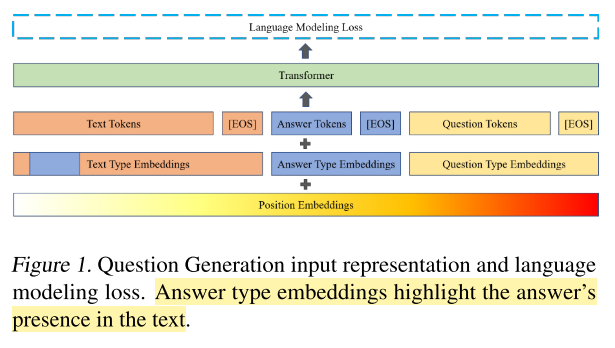
Question Generation
This paper uses token type ids to identify the components in the triplets. The answer span in the context are also marked by the answer token id. Special tokens is also added to the start and the end of the questions.
(Taken from the source paper)
Number of Triplets Generated
As explained in the previous section, the paper uses an over-generation technique to compensate for the model precision problem. Two questions are generated for each answer and context pair (a.k.a. answer candidate). Answer candidates of the context are generated by top-k sampling within a nucleus of p = 0.9 (that means we take the samples with the highest likelihoods until we either get K samples or the cumulative probabilities of the samples taken reaches 0.9).
(Taken from the source paper)
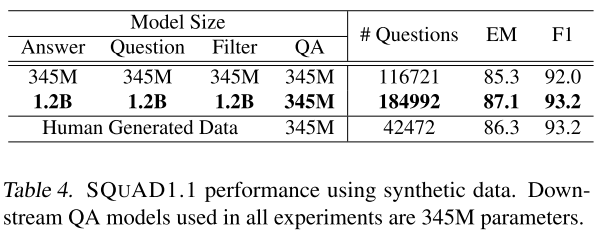
In the ablation study(which will be covered in the following sections), the models in stage 1 to 3 are trained with half of the SQuAD 1.1 training data, and the other half is used to generate synthetic data. The performance of the QA model trained on synthetic data is used to evaluate the quality of synthetic data.
From the table above (Table 4), we can see that the smaller model on average generated 2.75 valid triplets per context, and the larger model generated 4.36 triplets. Those synthetic datasets are already bigger than the SQuAD 1.1 training set.
Experiments
Model Scale
Table 4 (in the previous section) shows that larger models in stage 1 to 3 create better data for the downstream model, but it is not clear whether it was the quality of the data or the quantity of the data that helped.
(Taken from the source paper)
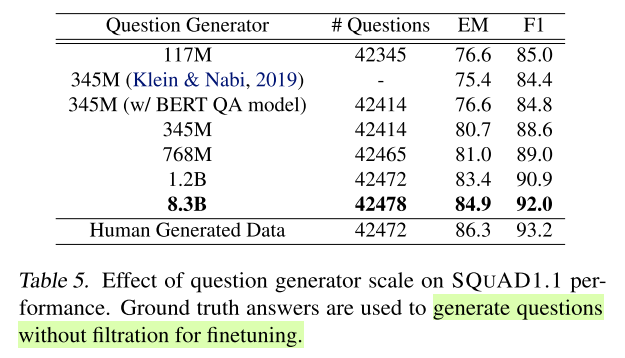
Table 5 shows that the quality of questions generated does increase as the model scales up.
(Taken from the source paper)
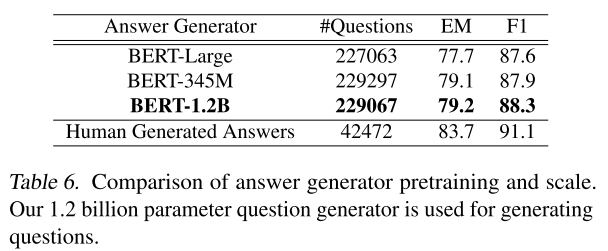
To test the quality of the generated answers, the paper used the 1.2B question generator (see Table 5) to generate questions without filtration from the generated answers, fine-tune a QA model and test against the dev set. Table 6 shows that bigger model increases the quality of generated answers, but only marginally.
(I am not sure how they obtained the benchmark for BERT-Large, though. I think BERT-Large expects a context and question pair to generate an answer, but here we want to generate answers from only the context. Maybe they take the pre-trained BERT-Large model and fine-tune it like the other two.)
(Taken from the source paper)
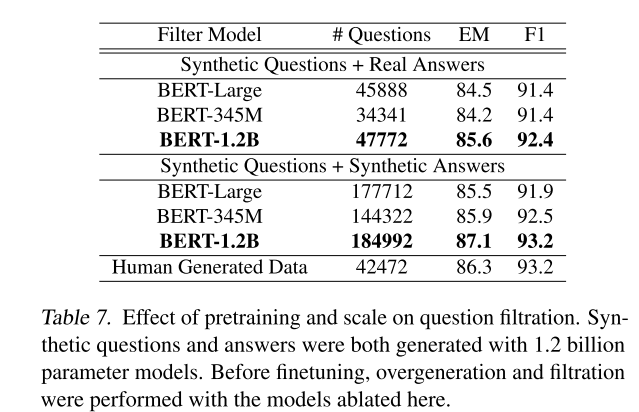
In Table 7 we can see that filtration does improve the performance of the downstream models (compare to Table 5). When using real answers to generate questions, less than 50% of the triplets generated by the 345M model were rejected, while about 55% by the 1.2B model was rejected. Note that all the models in this set under-performed to the model trained with only human-generated data (SQuAD training set).
The additional triplets from using generated answers are quite helpful, the 1.2B model finally surpassed the baseline model (human-generated data), but it used 3x+ more data.
To sum up, the ablation study shows that scaling up the model improved the quality of the generated data, but the increase in the quantity of the data also played a part.
Fully Synthetic Data
In this part of the paper, they trained the models for stage 1 to 3 using the full SQuAD 1.1 training set, and use the deduplicated Wikipedia documents as contexts to generate answers and questions. They also fine-tune an 8.3B GPT-2 model on Wikipedia documents to generate synthetic contexts.
(Taken from the source paper)
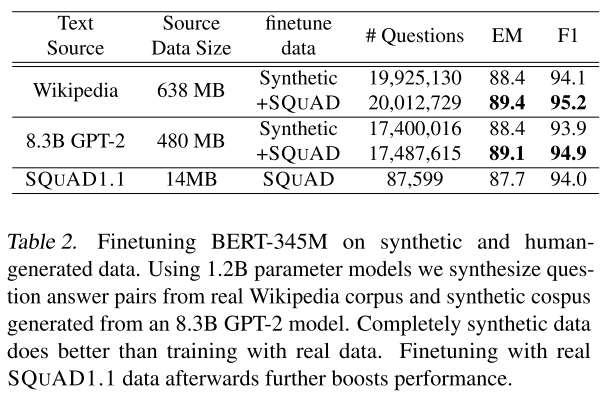
Table 2 shows that synthetic contexts can be as good as the real ones. Also, further fine-tuning on the real SQuAD 1.1 data can further improve the performance, which might imply that there is still something missing in the fully or partially synthetic triplets.
However, using 200x+ more data to get less 1% more accuracy seems wasteful. We want to know how much synthetic data we need to reach the baseline accuracy. The next section answers this question.
The Quantity of Data Required to Beat the Baseline
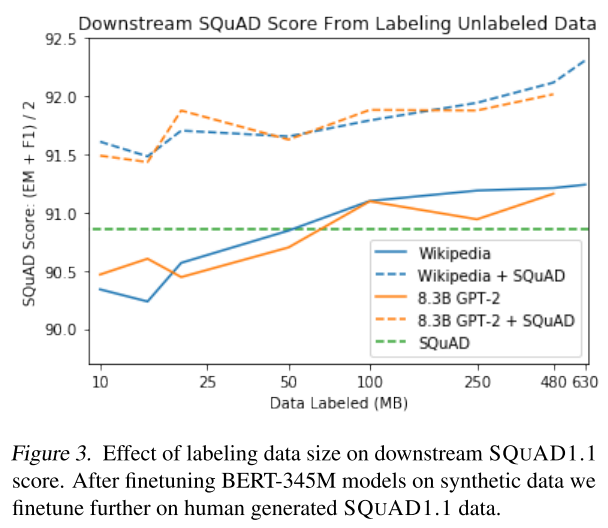
(Taken from the source paper)
(The “data labeled” seems to mean the size of the corpus used to generate the triplets, not the size of generated triplets.)
Figure 3 shows that we need at least 50 MB of text labeled to reach the baseline accuracy (without fine-tuning with the real data), 100 MB to surpass. That’s 2.5x+ and 7x+ more than the real one used by the baseline. Considering there are multiple triplets generated by one context, the number of triplets required is estimated (by me) to be around 20x and 40x more.
The silver lining is that only 10 MB of text is needed to be labeled if we fine-tune the model with the real SQuAD data to surpass the baseline. That roughly translates to 3 to 4 times more triplets used than the baseline. So real plus synthetic data is probably the way to go for now.
Wrapping Up
There are quite a few more details I did not cover in this post. Please refer to the source paper if you want to know more.
All in all, very interesting results in this paper. Unfortunately, the amount of compute needed to synthesize the data and the amount of synthetic data needed to reach good results are still staggering. But on the other hand, it is essentially trade compute for the human labors required by the annotation process, and it might not be a bad deal.