Recently I’m trying to pick up PyTorch as well as some object detection deep learning algorithms. So to kill two birds with one stone, I decided to read the Single Shot MultiBox Detector paper along with one of the PyTorch implementation written by Max deGroot.
Admittedly, I have some trouble understanding some ideas in the paper. After reading the implementation and scratching my head for a while, I think I figured out at least some parts of them. So the following is my notes on some confusing concept after my first and second pass of reading.
Network Structure
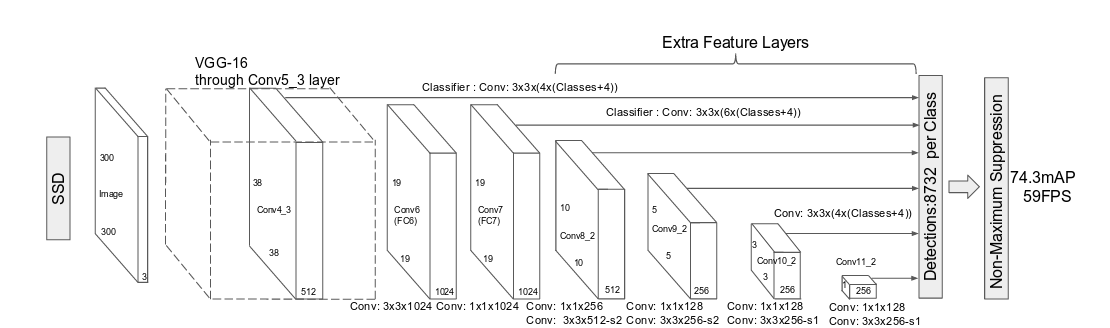
Firstly, Single Shot MultiBox Detector (SSD) uses VGG-16 structure pre-trained on the ILSVRC CLS-LOC dataset, and adds some extra convolution layers. The relevant code is located at ssd.py:
base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256,
'C', 512, 512, 512, 'M', 512, 512, 512],
'512': [],
}
extras = {
'300': [256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256],
'512': [],
}
‘M’ means max pooling with kernel size 2 and stride 2. ‘C’ means the same max pooling but with ceil_mode=True, which does not appear in the original structure. My understanding is thatceil_mode=True deals with cases where input height or width is not divisible by 2, so there will be some cells coming from 1x2, 2x1, 1x1 max pooling in the output. Not sure why it’s there, but shouldn’t make much difference.
‘S’ means a stride=2 and padding=1 convolution layer, the number of filters comes next in the list (for example, the first ‘S’ has 512 filters).
def vgg(cfg, i, batch_norm=False):
layers = []
in_channels = i
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(
kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(
in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [
conv2d, nn.BatchNorm2d(v),
nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(
512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7,
nn.ReLU(inplace=True)]
return layers
Note that it adds a conv6 (1024 3x3 convolution filters with dilation=6 and padding=6) and a conv7 (1024 1x1 convolution filters) layer to the original VGG structure.
def add_extras(cfg, i, batch_norm=False):
# Extra layers added to VGG for feature scaling
layers = []
in_channels = i
flag = False
for k, v in enumerate(cfg):
if in_channels != 'S':
if v == 'S':
layers += [
nn.Conv2d(in_channels, cfg[k + 1],
kernel_size=(1, 3)[flag], stride=2,
padding=1)]
else:
layers += [
nn.Conv2d(
in_channels, v, kernel_size=(1, 3)[flag])]
flag = not flag
in_channels = v
return layer
The construction of extra layers use a rotating 3x3 and 1x1 kernel size with optional the ‘S’ flag indicated stride=2 and padding=1 as we already mentioned.
We’ve covered the network structure. Now it’s time to move on to actually predict/detect the class and location of the objects.
Prediction Scheme
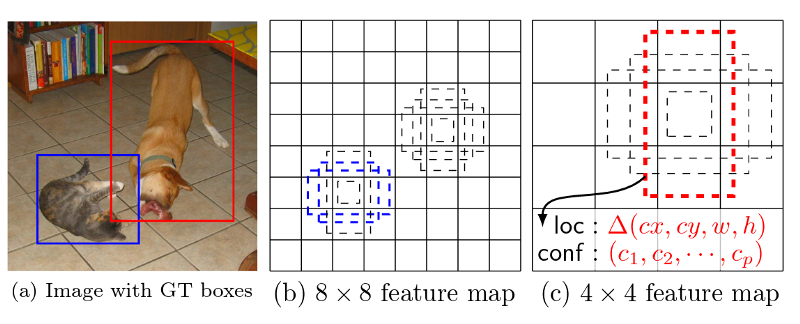
A key concept of SSD is taking intermediate layers in the neural network as feature maps. It then runs 3x3 convolution filters on the feature maps to classify and predict the offset to the default boxes (prior boxes in Python code). Each position has 4 or 6 corresponding default boxes. Naturally, default boxes in the lower layers are smaller because lower layers captures finer details of the input images.
For each default box we predict:
- the probability of it belong to a certain class
- the x and y offsets to the center of the default box
- the width and height scales to the width and height of the default box
The default box setup in ssd.py:
mbox = {
# number of boxes per feature map location
'300': [4, 6, 6, 6, 4, 4],
'512': [],
}
def multibox(vgg, extra_layers, cfg, num_classes):
loc_layers = []
conf_layers = []
vgg_source = [24, -2]
for k, v in enumerate(vgg_source):
loc_layers += [
nn.Conv2d(vgg[v].out_channels,
cfg[k] * 4, kernel_size=3, padding=1)]
conf_layers += [
nn.Conv2d(vgg[v].out_channels,
cfg[k] * num_classes, kernel_size=3,
padding=1)]
for k, v in enumerate(extra_layers[1::2], 2):
loc_layers += [
nn.Conv2d(v.out_channels, cfg[k]
* 4, kernel_size=3, padding=1)]
conf_layers += [
nn.Conv2d(v.out_channels, cfg[k]
* num_classes, kernel_size=3, padding=1)]
return vgg, extra_layers, (loc_layers, conf_layers)
def build_ssd(phase, size=300, num_classes=21):
if phase != "test" and phase != "train":
print("Error: Phase not recognized")
return
if size != 300:
print("Error: Sorry only SSD300 is supported currently!")
return
return SSD(
phase, *multibox(vgg(base[str(size)], 3),
add_extras(extras[str(size)], 1024),
mbox[str(size)], num_classes),
num_classes
)
SSD use two layers from the VGG model — Conv4_3 and Conv7/FC7, which correspond to layer index 24 and -2 (that is, before relu activation). This way of getting layers is a bit shaky. If we decided to use use batch_norm=True in VGG construction, the multibox construction would get the wrong layer. The same should go with extra layers as well, but in fact batch_norm=True has not even been implemented yet in add_extras() .
For extra layers, we use the second layer as feature map in every two layers. One weird part is that because final layer Conv11_2 has shape (256, 1, 1), so 3x3 convolution isn’t really necessary. I guess it just for the simplicity of code structure.
Note we should have num_class + 4 (x, y, w, h) outputs per default box.
Exercise
Try to verify the number of default boxes in SSD300 (the one implemented).
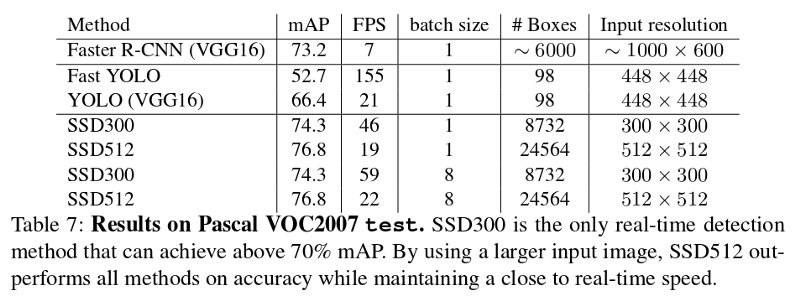
Solution
Conv4_3:38 * 38 * 4 = 5776Conv7:19 * 19 * 6 = 2166Conv8_2:10 * 10 * 6 = 600Conv9_2:5 * 5 * 6 = 150Conv10_2:3 * 3 * 4 = 36Conv11_2:4
Total: 5776+ 2166 + 600 + 150 + 36 + 4 = 8732
Note that this calculation includes default boxes from padded cells, which will always be zeros, thereby essentially useless boxes.
Additional exercise: calculate the number of valid default boxes in SSD300.
To be continued
We still haven’t discuss how to map those default boxes back to actual locations in the input images, how do we pick correct default boxes that matches the ground truth, and how to construct loss function to train the network. They will be addressed in the next post.
(2017/07/28 Update: Here are the links to the second part and the third part of the series.)
(2018/07/12 Update: Someone asked me an interesting question privately. With that person’s permission, the Q&A is reposted here:
Q: I tried to read both paper VGG-16 and SSD and everywhere it is mentioned that SSD used VGG-16 architecture but SSD architecture image from original paper starts from size (38 X 38 X 512) but only size available in VGG-16 architecture is (224x224x64),(112x112x128),(56x56x256) and so on but nowhere its (38x38x512).
A: Note the (official) input image size of VGG16 is 224, and the one of SSD is 300. For 224, the feature map evolve as (224, 224, 64), (112, 112, 128), (56, 56, 256) and (28, 28, 512) as you said. But if you put (300, 300, 3) image input into the VGG16 architecture. The feature map evolution becomes (300, 300, 64), (150, 150, 128), (75, 75, 256), (38, 38, 512).)