
Introduction
Self-supervised learning made transfer learning possible in NLP [1] (by using language modeling as the pre-training task) and has started to show some potential in CV as well [2, 3, 4]. They make the downstream tasks more label efficient, that is, requires fewer labeled examples to achieve good prediction accuracies.
In CV, we are already quite familiar with transfer learning from models pre-trained on the labeled Imagenet dataset. However, if the dataset used in the downstream task is significantly different from the Imagenet, transfer learning/fine-tuning usually would not be very helpful.
Inspired by the recent development in self-supervised learning in CV, I speculated that an unsupervised/self-supervised domain adaptation approach might be helpful in these cases. We take a model pre-trained on Imagenet, and run self-supervised learning on an unlabeled dataset from a different domain, in hope that this process will transfer some general CV knowledge into the new domain. The goal is to achieve more label efficiency in the downstream tasks within the new domain.
(Note: a similar approach is already widely used in NLP, in which we take a language model pre-trained a large corpus, and then train the language model further in a corpus from the same domain as the downstream task.)
My preliminary experiments show visible improvements from the self-supervised domain adaptation approach using images from the downstream task. With longer pre-training and bigger unlabelled datasets, we can probably get further improvements.
Experiments
Setup
- Dataset: A private image dataset with around 200 thousand images, with a negative class and multiple positive classes. It’s unbalanced (the size of the negative images are much larger).
- Model: Pre-trained BiT-M-R101x1 (model code) [5]. It replaced batch normalization layers with group normalization layers, thus performs better with smaller batch sizes.
- Self-supervision task: Bootstrap Your Own Latent (BYOL) algorithm [4] from DeepMind (implementation).
- Downstream classification metrics:
- Multi-class: log loss, F1
- Binary-class (positive/negative): AUC
![BYOL Architecture [4]](byol-arch.png)
BYOL Architecture [4]
Training steps:
- Load the pre-trained weights of the BiT-M-R101x1 model (without the classification head).
- BYOL: add projection layers and train on the dataset (without the labels).
- Remove the projection layers and add a classification head.
- Freeze all layers except the classification head and fine-tune the model on the labeled dataset.
- Unfreeze all layers and fine-tune the model on the labeled dataset.
(Because my local environment only has one RTX 2070 GPU, I can only fit a small number of examples in a batch. Picking architecture that is more friendly to smaller batch sizes becomes very crucial. Besides using BiT-M-R101x1 as the backbone, I also replace all the batch normalization layers in BYOL to layer normalization layers.)
Results
The following plots are from the last training step described in the previous section (I also include an EfficientNet-B4 model, which is the best model without self-supervised domain adaption, as a reference):
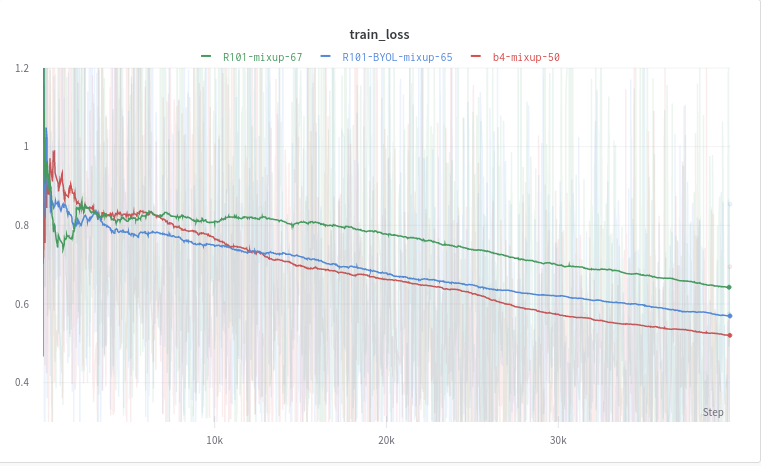
Train loss
We can see that the BYOL R101x1 model converged faster than both the Imagenet R101x1 model and the EfficientNet-B4 model.
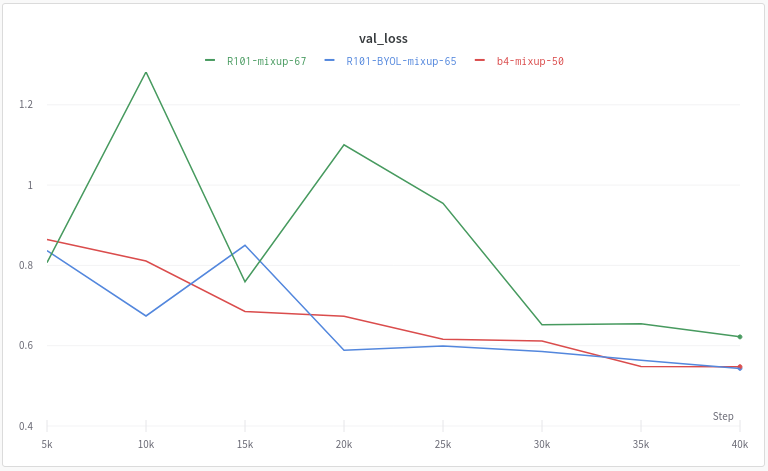
Validation Loss
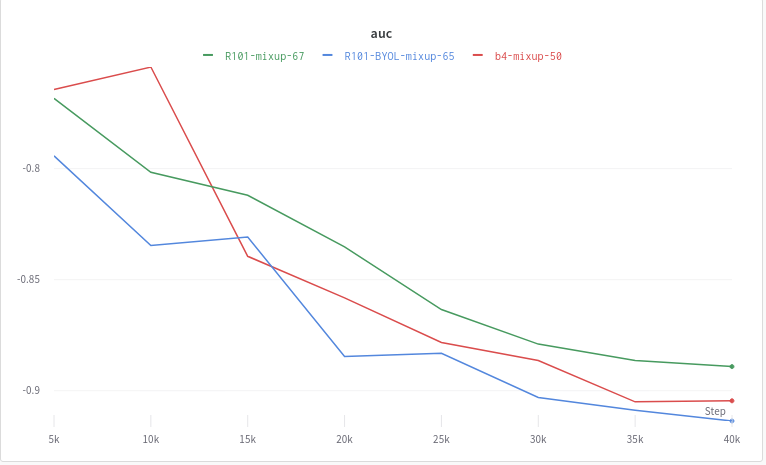
Validation AUC (flipped)
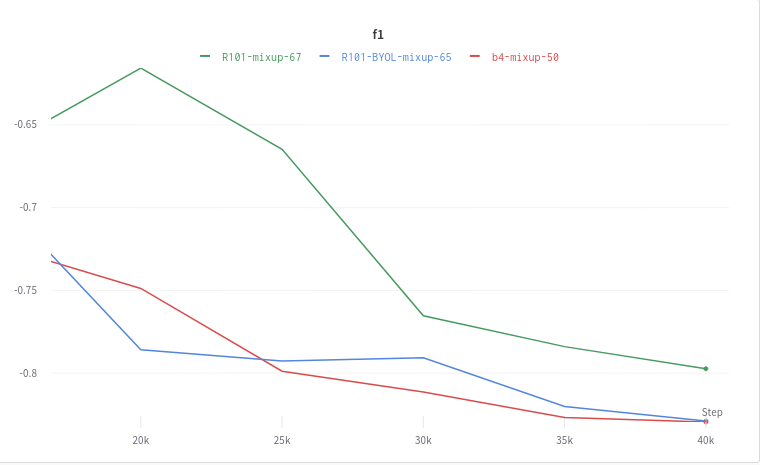
Validation F1 (flipped)
With test-time augmentation(TTA) (horizontal flip):
| Model | Loss | AUC | F1 |
|---|---|---|---|
| BIT-M-R101x1 | 0.4450 | 0.8970 | 0.7967 |
| BIT-M-R101x1 (BYOL) | 0.3793 | 0.9244 | 0.8308 |
| EfficientNet-B4 | 0.3972 | 0.9134 | 0.8355 |
Notes
The results are still preliminary. More experiments and ablation studies are needed to confirm the effectiveness of the self-supervised domain adaptation approach. However, current results show great potentials of this approach, as it already shows visible improvements.
Ideas/TO-DOs:
- Release all the code required to performs the entire procedure. (For now, you’ll have to find a way yourself to stitch the model code and BYOL code together.)
- Run the same experiments multiple times with different seed and take average (to make sure the improvement is robust).
- Run BYOL longer (currently I only trained it for about 5 epochs).
- Collect unlabeled data in the target domain that is much larger than the current downstream task and see if it helps the downstream task.
- Try some downstream tasks with much fewer labeled examples (or just use a small subset from the current dataset).
- Try EfficientNet-B3 and EfficientNet-B4. My hypothesis is that because of the existence of batch normalization layers, the benefits from BYOL to the B4 model will not be as great as the B3 model (which can be trained with larger batch sizes).
- Find a way to fit the self-supervised domain adaptation approach into multimodal settings (text + images, audio + images, etc.).
References
- Howard, J., & Ruder, S. (2018). Universal Language Model Fine-tuning for Text Classification.
- Chen, T., Kornblith, S., Swersky, K., Norouzi, M., & Hinton, G. (2020). Big Self-Supervised Models are Strong Semi-Supervised Learners.
- Chen, M., Radford, A., Child, R., Wu, J., Jun, H., Dhariwal, P., Luan, D., & Sutskever, I. (2020). Generative Pretraining from Pixels.
- Grill, J.-B., Strub, F., Altché, F., Tallec, C., Richemond, P. H., Buchatskaya, E., … Valko, M. (2020). Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning.
- Kolesnikov, A., Beyer, L., Zhai, X., Puigcerver, J., Yung, J., Gelly, S., & Houlsby, N. (2019). Big Transfer (BiT): General Visual Representation Learning.