
Synopsis
I have the task of finding similar entries among 8,000+ pieces of news, using their title and edited short descriptions in Traditional Chinese. I tried LASER[1] first but later found Universal Sentence Encoder[2] seemed to work slightly better. Results from these unsupervised approaches are already acceptable, but still have occasional confusion and hiccups.
Not entirely satisfied with the unsupervised approaches, I collected and annotated 2,000 pairs of news and fine-tuned the BERT model on this dataset. This supervised approach is visibly better than the unsupervised one. And it’s also quite sample-efficient. Three hundred and fifty training example is already enough to beat Universal Sentence Encoder by a large margin.
Collecting domain-specific training examples, albeit small in size, can be crucial in improving the model performance. The result in this post provides some evidence to this argument.
Background
The Sentence-BERT paper[3] demonstrated that fine-tune the BERT[4] model on NLI datasets can create very competitive sentence embeddings. Further fine-tuning the model on STS (Semantic Textual Similarity) is also shown to perform even better in the target domain.
![from Reimers et al.[3]](stsb_table.png)
from Reimers et al.[3]
I reviewed BERT and Sentence-BERT in this previous post: Zero Shot Cross-Lingual Transfer with Multilingual BERT. Readers are also advised to read that post for more information about the advantages of using sentence embeddings instead of directly feeding sentence pairs to BERT.
Experiments
Dataset
Each pair of news is annotated with one of these scores — {0, 0.25, 0.5, 0.75, 1.0}, according to these general rules:
- 0 — These two pieces of news are completely unrelated.
- 0.25 — These two pieces of news share a very general topic (e.g. diplomatic incidences) or a larger region (e.g. South-East Asia).
- 0.5 — These two pieces of news share a topic (e.g. health tips), a country (e.g. South Korea), or a set of countries (e.g. Japan and the U.S.A.).
- 0.75 — These two pieces of news share a topic AND a country / a set of countries (e.g. trade negotiation between China and the U.S.A.).
- 1 — These two pieces of news cover the same events (e.g. the meeting of Trump and Kim) or shares the very narrow topic (e.g. the impact of Brexit on consumers).
The 2,000 annotated pairs were split into three parts: training (1,400 pairs), validation (300 pairs), and test (300 pairs).
Supervised Model
The model setup is basically the same as in [3]. The cosine similarity between the sentence embeddings is used to calculate the regression loss (MSE is used in this post).
Since we only care about relative rankings, I also tried applying a learnable linear transformation to the cosine similarities to speed up training. The results are more or less the same. To reduce the hyper-parameters involved, The results reported below were all from trained without the linear transformation.
The model with the best validation result is picked as the final model.
Results
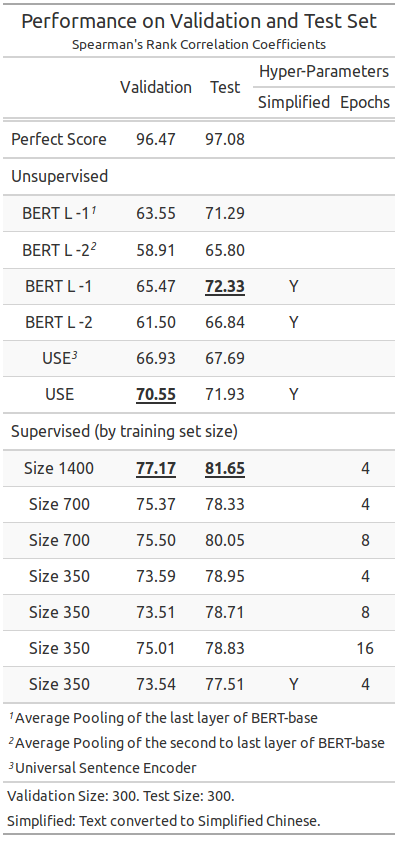
The BERT baseline is formulated as in bert-as-service[5]. Using the second-to-last layer does not have better performance for this dataset.
Interestingly, converting the text from Traditional Chinese to Simplified Chinese boosts the performance of the unsupervised BERT and USE models. This might indicate the relative lack of Traditional Chinese resources during pre-training. In contrast, doing the same in supervised training creates slightly worse models.
I fixed the validation and test set, and sampled the training set to see how the supervised performs in low resource settings. The experiments show that it can already beat the unsupervised models with 350 examples, and more examples steadily improve the performance.
Things that didn’t work
- Using Sentence-BERT fine-tuned on XNLI dataset.
- Using Sentence-BERT fine-tuned on LCQMC dataset[6].
- Using Sentence-BERT fine-tuned on a news classification dataset.
The news classification dataset is created from the same 8,000+ pieces of news used in the similarity dataset. The models are further fine-tuning on the similarity dataset.
Among these three, the model fine-tuned on news classification dataset is the best one, but still inferior to directly fine-tuning on the similarity dataset.
The failure of this approach to improve the performance can probably be attributed to the relatively large domain mismatch and the low quality of the machine-translated XNLI training set.
Fin
As stated in the synopsis, I think that collecting domain-specific training examples, albeit small in size, can be crucial in improving the model performance. Although dull and boring at times, collecting and annotating your own dataset can be a very rewarding experience. Knowing your data is one of the most underrated aspects of data science IMHO.
References
- Artetxe, M. (2018). Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond.
- Yang, Y., Cer, D., Ahmad, A., Guo, M., Law, J., Constant, N., … Kurzweil, R. (2019). Multilingual Universal Sentence Encoder for Semantic Retrieval.
- Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks.
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- hanxiao/bert-as-service: Mapping a variable-length sentence to a fixed-length vector using BERT model.
- Liu, X. U., Chen, Q., Deng, C., Zeng, H., Chen, J. J., Li, D., & Tang, B. (2018). LCQMC: A Large-scale Chinese Question Matching Corpus. Proceedings of the 27th International Conference on Computational Linguistics, 1952–1962.