
In this post we establish a topic similarity measure among the news articles collected from the New York Times RSS feeds. The main purpose is to familiarized ourselves with the (PyTorch) BERT implementation and pretrained model(s).
What is BERT?
BERT stands for Bidirectional Encoder Representations from Transformers. It comes from a paper published by Google AI Language in 2018[1]. It is based on the idea that fine-tuning a pretrained language model can help the model achieve better results in the downstream tasks[2][3].
We’ve seen transformers[4] used to train (unidirectional) language models in the OpenAI paper[3]. BERT uses a clever task design (masked language model) to enable training of bidirectional models, and also adds a next sentence prediction task to improve sentence-level understanding. As a result, BERT obtains new state-of-the-art results on eleven natural language processing tasks.
Here is a great series on BERT. If you’re already familiar with language models, you can start with Part 2 (otherwise you might want to check out Part 1): Dissecting BERT Part 2: BERT Specifics.
We’ve also covered the OpenAI before in this post: [Notes] Improving Language Understanding by Generative Pre-Training.
Problem Description
The New York Times RSS feed provide us with the a list of of news articles, and their titles, descriptions, published dates, links, and categories. Given an article, we want to automatically find other articles covering the same topic without relying on the category information (so we can apply the algorithm to multiple sources in the future).
An example:
Title: What Is and Isn’t Affected by the Government Shutdown
Description: Transportation Security Administration officers checking passengers at Pittsburgh International Airport last week. The agency’s employees have called out sick in increased numbers across the country since the shutdown began.
Next Sentence Prediction
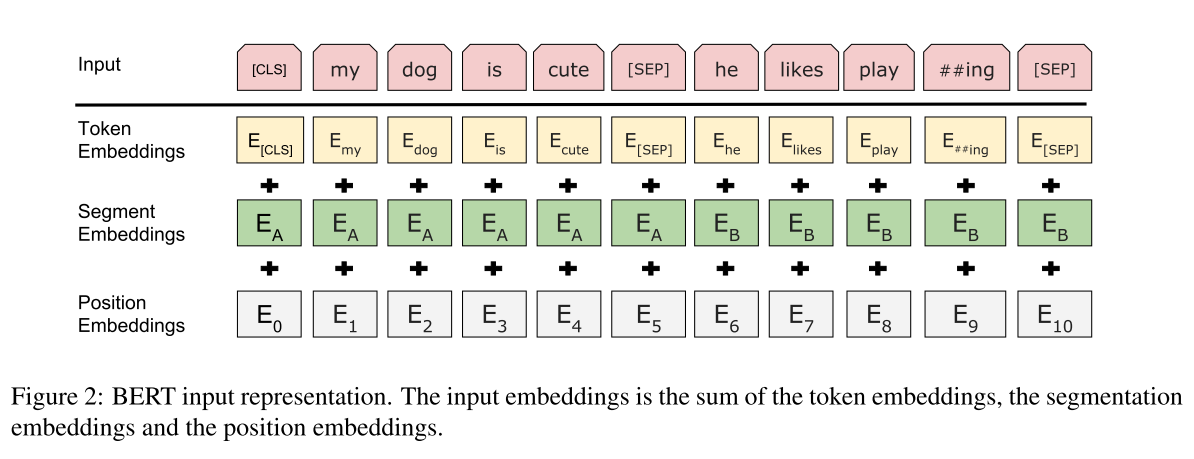
Firstly, we need to take a look at how BERT construct its input (in the pretraining stage). An input sequences consists of two “sentences”(explained below), each ends with a [SEP] token. And a [CLS] token is added to the head, whose corresponding hidden states are used to make the next sentence prediction.
To generate each training input sequence, we sample two spans of text from the corpus, which we refer to as “sentences” even though they are typically much longer than single sentences (but can be shorter also). [1]
The pretrained BERT model, according to the paper[1], achieves 97%~98% accuracy at this task with a balanced dataset.
Proposed Solution
We fill the first sentence with the title of the article, and the second with the description. Ideally, the title-description pairs that came from the same article should have a high next sentence score from a pretrained models (i.e. the description is deemed highly likely the next sentence of the title). If not, we’ll need to fine-tune the pretrained model (train the model further with the new data).
Intuitively, if two news article covers the same topic, the title from one article and the description from another combined should also have a high next sentence score, since they are sentimentally similar.
This is the converted input sequence of the previous example:
[CLS] what is and isn ’ t affected by the government shut ##down [SEP] transportation security administration officers checking passengers at pittsburgh international airport last week . the agency ’ s employees have called out sick in increased numbers across the country since the shut ##down began .[SEP]
And this is the above input sequence with the second sentence replaced by the description from another article:
[CLS] what is and isn ’ t affected by the government shut ##down [SEP] gr ##udge ##s can be good . they are one habit that humans have evolved to keep ourselves from the pain of breakup ##s and also from eating mo ##zza ##rella sticks for every meal . [SEP]
Results
I first tried using the pretrained model without any fine-tuning, and it already worked great. The dataset consists of 2,719 articles from the New York Times RSS feeds, with articles with no or very short descriptions removed.
For the correct pairs (the title and description came from the same article), only 2.5% of them were give a lower than 50% next sentence score by the pretrained model (BERT-base-uncased). 97.3% of them has a scores above 90%. The following is an example that was predicted negative:
Title: Meanwhile: For a Knife, Dagger, Sword, Machete or Zombie-Killer, Just Ask These Ladies
Description: Whitehead’s Cutlery in Butte, Mont., is 128 years old and will gladly sharpen scissors sold generations ago.
It’s more tricky to evaluate other pairs, since we have no labeled data regarding to the similarity between articles. We can only qualitatively examine some of the pairs.
As an example, I use the title from the previous shown government shutdown article and generate 2,719 input sequences with the descriptions from the whole corpus. Here are the top five matches (highest next sentence scores):
Top 5 Descriptions Matching this Title: **What Is and Isn’t Affected by the Government Shutdown**
1. Transportation Security Administration agents are among the most visible federal employees affected by the government shutdown.
2. Transportation Security Administration agents at Chicago Midway International Airport on Dec. 22, the first day of the government shutdown.
3. Damage from Hurricane Michael lingers throughout Marianna, Fla. The government shutdown has made things worse for many residents.
4. Scientists aboard a National Oceanic and Atmospheric Administration ship in San Juan, P.R. The administration has furloughed many workers because of the government shutdown.
5. Major federal agencies affected by the shutdown include the Departments of Agriculture, Commerce, Homeland Security, Housing and Urban Development, the Interior, Justice, State, Transportation, and the Treasury and the Environmental Protection Agency.
Interestingly, the actual description from the article did not make top 5 nor top 10. But still, the predicted descriptions seem reasonably good.
Source Code
The code is based on the PyTorch implementation of BERT by Hugging Face: huggingface/pytorch-pretrained-BERT.
The pretrained model parameters are from the official Tensorflow implementation from Google: google-research/bert.
The Jupyter Notebook used for this post: ceshine/pytorch-pretrained-BERT
The notebook used some preprocessing functions from the example script for sentence classification fine-tuning.
Conclusions and Future Work
In this post we’ve demonstrated that the next sentence prediction task in BERT pretraining stage successfully captured semantic information in sentences, and can be used to determine the similarity of two articles.
In fact, one of the downstream task BERT was evaluated upon is Quora Question Pairs[5], which asks the model to determine if two questions are asking the same thing. If we can manually label some data, the results might be even better.
Other more efficient way (in terms of computation required) way to measure document or sentence similarity is doing sentence embeddings. In contrast to RNN and its variants (e.g. LSTM and GRU), extracting sentence embeddings from transformer models is not as straight forward (see this discussion).
2019/03/23 Update
Here is an awesome project that use BERT to generate sentence embeddings and serve the model in scale: hanxiao/bert-as-service.
References
-
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
-
Howard, J., & Ruder, S. (2018). Universal Language Model Fine-tuning for Text Classification.
-
Radford, A., & Salimans, T. (2018). Improving Language Understanding by Generative Pre-Training.
-
Z. Chen, H. Zhang, X. Zhang, and L. Zhao. 2018. Quora question pairs.