 Photo by Sam Power on Unsplash
Photo by Sam Power on Unsplash
The Apex project from NVIDIA is touted as a PyTorch extension that let developers do mixed precision and distributed training “with 4 or fewer line changes to the existing code”. It’s been out for a while (circa June 2018) and seems to be well received (huggingface/pytorch-pretrained-BERT uses Apex to do 16-bit training). So I decided to give it a try. This post documents what I’ve learned.
Spoiler: The answer to the question in the subtitle — yes and no. Yes, Apex and mixed precision training help you save GPU memory and thus allow bigger models and bigger batches under the same hardware limitation. But no, it most likely won’t speed up the training on a pre-Volta graphic card, unless the model is heavy on bandwidth operations.
What is Mixed Precision Training
Check out this great overview by Sylvain Gugger: Mixed precision training (forums.fast.ai)
Generally GPUs are good at doing 32-bit(single precision) math, not at 16-bit(half) nor 64-bit(double precision). Therefore traditionally deep learning model trainings are done in 32-bit.
By switching to 16-bit, we’ll be using half the memory and theoretically less computation at the expense of the available number range and precision. However, pure 16-bit training creates a lot of problems for us (imprecise weight updates, gradient underflow and overflow). Mixed precision training alleviate these problems.
Tweaks to the training loop needed for mixed precision training: pic.twitter.com/aRWf1PAKu1
— Rachel Thomas (@math_rachel) March 12, 2019
For a more technical introduction, refer to “Mixed-Precision Training of Deep Neural Networks” by Paulius Micikevicius.
How to Use Apex
In this post we’ll only cover the mixed precision training part of Apex, not the distributed training part (since I only have one GPU).
Optimization Levels
Apex recently changed its API to a unified one for all “optimization levels”. And the “4 lines of code” in the punchline has reduced to “3 lines of code”.
The four optimization levels:
-
O0 (FP32 training): basically a no-op. Everything is FP32 just as before.
-
O1 (Conservative Mixed Precision): only some whitelist ops are done in FP16.
-
O2 (Fast Mixed Precision): this is the standard mixed precision training. It maintains FP32 master weights and optimizer.step acts directly on the FP32 master weights.
-
O3 (FP16 training): full FP16. Passing
keep_batchnorm_fp32=Truecan speed things up as cudnn batchnorm is faster anyway.
Changes to the Existing Code
I modified thesimple PyTorch wrapper I wrote(ceshine/pytorch_helper_bot) and made it compatible with Apex (using the new API). Here’s how I do it.
First of all, try to import Apex and set a flag if successful (“amp” stands for Automatic Mixed Precision):
I use a class attribute use_amp to tell the trainer that I have passed amp-modified model and optimizer to it (APEX_AVAILABLE must be true if use_amp is true). The next step is updating the back-propagation part of the code:
Finally, we need to initialize the PyTorch model and optimizer outside of the wrapper:
That’s it! This is the minimal code changes required to do mixed precision training with Apex.
Advanced Usage
Unfortunately, for some common deep learning training techniques, Apex requires more changes to be made. Here we’ll cover gradient clipping and learning rate schedulers.
For gradient clipping, we need to use amp.master_params to retrieve the master weights and the unscaled gradients (in FP32):
At some optimization levels the optimizer returned by amp.initialize is an apex.fp16_utils.fp16_optimizer import FP16_Optimizer instance, which will break the standard learning rate schedulers since it’s not a subclass of torch.optim.Optimizer. A hacky way to solve this is to override the constructor (__init__):
Honestly I did not write tests to check if learning rate schedulers works the same way with FP16_Opimizer instances, but in my experiment they seem to work the way as expected.
Experiments
I tried to train some models on the Cifar10 dataset with Apex. The GPU used is a GTX 1070 (Pascal architecture). The code is not really publication-ready yet, but here’s the link for those who are interested: ceshine/apex_pytorch_cifar_experiment.
Some not-rigorous-at-all statistics:
-
seresnext50_32x4d, FP32, Adam: _79.71% validation accuracy 9m1s training time 3142MB GPU memory usage
-
seresnext50_32x4d, O1, Adam: _79.82% validation accuracy 10m19s training time 2514MB GPU memory usage
-
seresnext50_32x4d, O2, Adam: _80.20% validation accuracy 9m35s training time 2615MB GPU memory usage
-
seresnext50_32x4d, O3/FP16, SGD: _79.71% validation accuracy 9m54s training time 2490MB GPU memory usage
-
Densenet161, FP32 (Batch Size 512 Epochs: 25): 85.32% 29m32s 4170MB
-
Densenet161, O2 (Batch Size 1024 Epochs: 50): 85.92% 37m15s 4242MB
So no speed gain by switching to FP16 or O1/O2, but the memory usage did drop significantly. This is consistent with the numbers reported in znxlwm/pytorch-apex-experiment which conducted extensive experiments on different GPUs and precision levels with a VGG16 model.
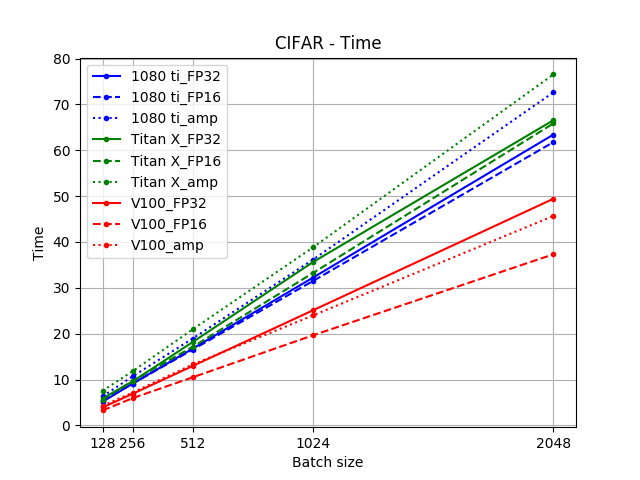
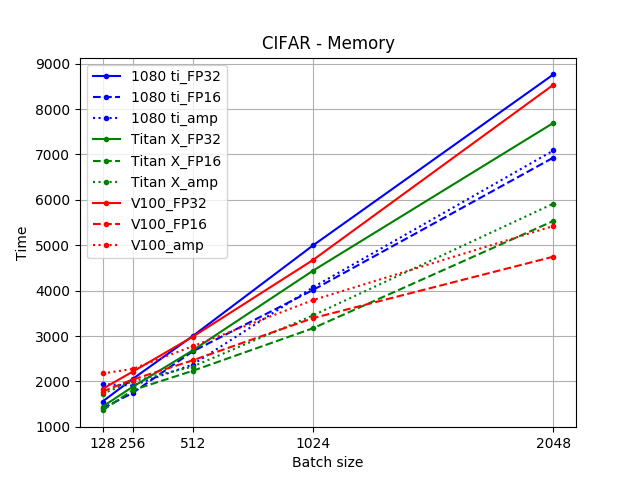
source (The unit of the y-axis is actually MB)
For both Titan X and GTX 1080 Ti, the automatic mixed precision (Amp) trainings were slower than both FP32 and FP16 training, while the latter two were roughly the same speed. The amount of memory saved from using Amp was higher with V100 than Titan X and GTX 1080 Ti.
Why the Discrepancy?
NVIDIA introduced “Tensor Cores” in Volta architecture, which are optimized to do mixed precision computing. The later consumer Turing architecture also have them. Reference: Tensor Cores in NVIDIA Volta GPU Architecture.
The following thread addressed the question quite well: Do I need tensor cores to benefit from Mixed-Precision training? · Issue ##76 · NVIDIA/apex.
Some non-Volta cards (like the P100) can benefit from half-precision arithmetic for certain networks, but the numerical stability is much less reliable (even with Apex tools)
This is probably why I only manage to get SGD to work with FP16 (Adam works fine with O2 and O3, though).
In the Pascal cards, the FP16 operations are actually done in FP32, so you only saves the memory and bandwidth, not the computation. The extra overhead of converting precision (in PyTorch) also slows down the process.
For FP16 tensors, this traffic is FP16. Once the data reaches the cores, it is stored in registers as FP32, operated on in FP32, and written back to dram once again as FP16.
(This post is also published on Medium.)