In the previous post we discussed the network structure and the prediction scheme of SSD. Now we move on to combine default boxes and the ground truth, so the quality of the prediction can be determined (and be improved via training).
(Reminder: The SSD paper and the Pytorch implementation used in this post)
Map Default Boxes to Coordinates On Input Images
Parameters of default boxes for each feature map are pre-calculated and hard-coded in data/config.py:
#SSD300 CONFIGS
# newer version: use additional conv11_2 layer as last layer before multibox layers
v2 = {
'feature_maps' : [38, 19, 10, 5, 3, 1],
'min_dim' : 300,
'steps' : [8, 16, 32, 64, 100, 300],
'min_sizes' : [30, 60, 111, 162, 213, 264],
'max_sizes' : [60, 111, 162, 213, 264, 315],
'aspect_ratios' : [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance' : [0.1, 0.2],
'clip' : True,
'name' : 'v2',
}
The actual mapping happens in layers/functions/prior_box.py (P.S. default boxes are called prior boxed in the implementation):
from itertools import product as product
class PriorBox(object):
def __init__(self, cfg):
super(PriorBox, self).__init__()
# self.type = cfg.name
self.image_size = cfg['min_dim']
self.variance = cfg['variance'] or [0.1]
# […]
for v in self.variance:
if v <= 0:
raise ValueError(
'Variances must be greater than 0')
def forward(self):
mean = []
if self.version == 'v2':
for k, f in enumerate(self.feature_maps):
for i, j in product(range(f), repeat=2):
f_k = self.image_size / self.steps[k]
# unit center x,y
cx = (j + 0.5) / f_k
cy = (i + 0.5) / f_k
# aspect_ratio: 1
# rel size: min_size
s_k = self.min_sizes[k]/self.image_size
mean += [cx, cy, s_k, s_k]
# aspect_ratio: 1
# rel size: sqrt(s_k * s_(k+1))
s_k_prime = sqrt(
s_k * (self.max_sizes[k]/self.image_size))
mean += [cx, cy, s_k_prime, s_k_prime]
# rest of aspect ratios
for ar in self.aspect_ratios[k]:
mean += [
cx, cy, s_k*sqrt(ar), s_k/sqrt(ar)]
mean += [
cx, cy, s_k/sqrt(ar), s_k*sqrt(ar)]
# […]
# back to torch land
output = torch.Tensor(mean).view(-1, 4)
if self.clip:
output.clamp_(max=1, min=0)
return output
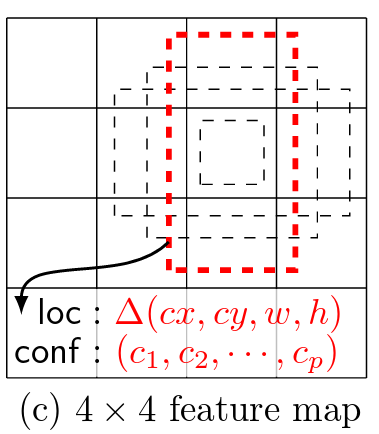
Layout of the four default boxes (from original paper)
(itertools.product creates Cartesian product of input iterables. So product(range(4), repeat=2) yields all the combinations between (0, 1, 2, 3) and (0, 1, 2, 3), that is, (0, 0), (0, 1) …, (3, 2), (3, 3).)
Take the first feature map (38x38) as an example. f_k=300/8=37.5 . i+0.5 and j+0.5 range from 0.5 to 37.5. So the center point coordinates cx and cy translate to (0.0133, 0.0133), (0.0133, 0.04) …, (1, 0.9733), (1, 1). Note the code normalize the coordinates to [0, 1], and remember that most of the feature maps are zero padded (the outermost cells are always zero). You can verify yourself that the outermost center points in the second last (not padded) feature map is a bit away from 0 and 1. And the last feature map has only one center point located exactly at (0.5, 0.5).
Now we have the center points of every default boxes. Next we want to calculate the widths and heights. There are six default box layouts:
- Small square of size
(s_k, s_k) - Large square of size
(sqrt(s_k * s_(k+1)), sqrt(s_k * s_(k+1))) - 1:2 Rectangle of size
(s_k * 0.7071, s_k * 1.414) - 2:1 Rectangle of size
(s_k * 1.414, s_k * 0.7071) - 1:3 Rectangle of size
(s_k * 0.5774, s_k * 1.7321) - 3:1 Rectangle of size
(s_k * 1.7321, s_k * 0.5774)
For feature maps with 4 default boxes, only the first four layouts are used. The areas of rectangles are the same as the small square. This is different from the figure above, where the area seems to be the same as the large square.
The s_ks come from the following formula, with exception of the first feature map:
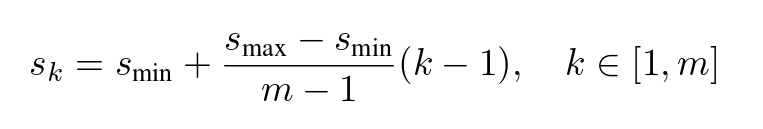
Formula (4) from the original paper
The default boxes are in fact designed empirically, as stated in the paper:
In practice, one can also design a distribution of default boxes to best fit a specific dataset. How to design the optimal tiling is an open question as well.
So you may modify prior_box.py freely to suit your needs.
Find the Default Boxes that Best Match the Ground Truth
This is called “matching strategy” in the paper. The idea is really simple — Any pair of ground truth box and default box is considered a match if the their Jaccard overlap is larger than a threshold(0.5). In (hopefully) plain English, it’s a match if the overlap area is larger than half of the area that both of the boxes covered.
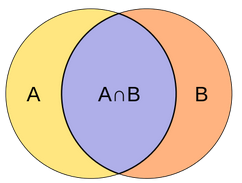
The intersection need to be larger than half of the union. (Image from Wikipedia)
The relevant code is located at layers/box_utils.py:
def intersect(box_a, box_b):
""" We resize both tensors to [A,B,2] without new malloc:
[A,2] -> [A,1,2] -> [A,B,2]
[B,2] -> [1,B,2] -> [A,B,2]
Then we compute the area of intersect between box_a and box_b.
Args:
box_a: (tensor) bounding boxes, Shape: [A,4].
box_b: (tensor) bounding boxes, Shape: [B,4].
Return:
(tensor) intersection area, Shape: [A,B].
"""
A = box_a.size(0)
B = box_b.size(0)
max_xy = torch.min(box_a[:, 2:].unsqueeze(1).expand(A, B, 2),
box_b[:, 2:].unsqueeze(0).expand(A, B, 2))
min_xy = torch.max(box_a[:, :2].unsqueeze(1).expand(A, B, 2),
box_b[:, :2].unsqueeze(0).expand(A, B, 2))
inter = torch.clamp((max_xy - min_xy), min=0)
return inter[:, :, 0] * inter[:, :, 1]
(Tensor.unsqueeze inserts a new dimension of size 1 at the specified position. It should be equivalent to numpy.expand_dims. Tensor.expand expand size 1 dimension in a memory efficient way. When combined they are functionally equivalent to Tensor.repeat, but Tensor.repeat creates a new tensor.)
(Tensor.clamp restrict the maximum and minimum values of a tensor. Should be equivalent to numpy.clip.)
The author calculates the intersection in a clever way. By expanding the tensors, we now are able to calculate the intersections of every combination of box_a(ground truth) and box_b(default boxes) in one run without any for loop.
def jaccard(box_a, box_b):
"""Compute the jaccard overlap of two sets of boxes.
The jaccard overlap is simply the intersection over
union of two boxes. Here we operate on ground truth
boxes and default boxes.
E.g.:
A ∩ B / A ∪ B = A ∩ B / (area(A) + area(B) - A ∩ B)
Args:
box_a: (tensor) Ground truth bounding boxes,
Shape: [num_objects,4]
box_b: (tensor) Prior boxes from priorbox layers,
Shape: [num_priors,4]
Return:
jaccard overlap: (tensor)
Shape: [box_a.size(0), box_b.size(0)]
"""
inter = intersect(box_a, box_b)
area_a = ((box_a[:, 2] - box_a[:, 0]) *
(box_a[:, 3] -
box_a[:, 1])).unsqueeze(1).expand_as(inter)
area_b = ((box_b[:, 2] - box_b[:, 0]) *
(box_b[:, 3] -
box_b[:, 1])).unsqueeze(0).expand_as(inter)
union = area_a + area_b - inter
return inter / union # [A,B]
Here the author use the same trick to calculate the area of every boxes in one run and then get the union.
def match(threshold, truths, priors, variances,
labels, loc_t, conf_t, idx):
"""Match each prior box with the ground truth box of
the highest jaccard overlap, encode the bounding boxes,
then return the matched indices corresponding to both
confidence and location preds.
Args:
threshold: (float) The overlap threshold
used when mathing boxes.
truths: (tensor) Ground truth boxes,
Shape: [num_obj, num_priors].
priors: (tensor) Prior boxes from priorbox layers,
Shape: [n_priors,4].
variances: (tensor) Variances corresponding
to each prior coord,
Shape: [num_priors, 4].
labels: (tensor) All the class labels for the image,
Shape: [num_obj].
loc_t: (tensor) Tensor to be filled w/ encoded
location targets.
conf_t: (tensor) Tensor to be filled w/ matched
indices for conf preds.
idx: (int) current batch index
Return:
The matched indices corresponding to
1)location and 2)confidence preds.
"""
# jaccard index
overlaps = jaccard(
truths,
point_form(priors)
)
# (Bipartite Matching)
# [num_objects, 1] best prior for each ground truth
best_prior_overlap, best_prior_idx = overlaps.max(1)
# [1, num_priors] best ground truth for each prior
best_truth_overlap, best_truth_idx = overlaps.max(0)
best_truth_idx.squeeze_(0)
best_truth_overlap.squeeze_(0)
best_prior_idx.squeeze_(1)
best_prior_overlap.squeeze_(1)
# ensure best prior
best_truth_overlap.index_fill_(0, best_prior_idx, 2)
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j
# Shape: [num_priors,4]
matches = truths[best_truth_idx]
# Shape: [num_priors]
conf = labels[best_truth_idx] + 1
# label as background
conf[best_truth_overlap < threshold] = 0
loc = encode(matches, priors, variances)
# [num_priors,4] encoded offsets to learn
loc_t[idx] = loc
# [num_priors] top class label for each prior
conf_t[idx] = conf
(Tensor.max and Tensor.min when passed a dim parameter return two tensors: 1. the actual max/min values along the designated axis. 2. the index of the max/min values along that axis)
([Tensor.squeeze(http://pytorch.org/docs/master/tensors.html#torch.Tensor.squeeze_) is the in-place version of Tensor.squeeze, which returns a tensor with all the dimension of size 1 removed.)_
(Tensor.index_fill fills the elements of the original tensor with the value passed at the indices passed)
Remember what we get from prior_box.py is in (cx, cy, w, h) format? Here we use point_from to convert it into (xmin, ymin, xmax, ymax) format. The code is not posted to save space (find it here).
This part of the code might be the most confusing:
# ensure best prior
best_truth_overlap.index_fill_(0, best_prior_idx, 2)
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j
The tensor best_prior_idx contains the index of the best matched default box for each ground truth box. So what the first line of code does is to make sure every ground truth box has a least one default box that passed the threshold.
The for loop propagates the changes from the first line back to the tensor best_truth_idx, which contains the index of the best matched ground truth box for each default box. The effect of this loop is forcing the prior box give up the original best matching ground truth when there exists another ground truth that need it more (otherwise no default box for that ground truth).
Note that we match each default box to exactly one ground truth, and assign a special label/class zero for all default boxes with maximum Jaccard overlap less than the threshold (thus background).
There is an encode function which transform the matched ground truth and default box pair into a format the loss function understands. The loss function will be discussed in the next post.
To Be Continued
We discussed how to map default box to actual coordinates and how to match the ground truth boxes and default boxes. It took longer than I expected, so there will be a part 3 discussing objective function and finally how to predict/detect in the test phase.
(2017/07/28 Update: Here’s the link to the third part of the series)