(Reminder: The SSD paper and the Pytorch implementation used in this post. Also, the first and second part of the series.)
Training Objective / Loss Function
Every deep learning / neural network needs a differentiable objective function to learn from. After pairing ground truths and default boxes, and marking the remaining default boxes as background, we’re ready to formulate the objective function of SSD:
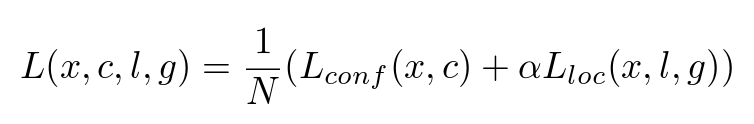
Overall Objective — Formula (1) from the original paper
There are two parts of this objective function:
- The confidence loss: How accurate does the model predict the class of the each object
- The localization loss: How close are the bounding boxes the model created to the ground truth boxes.
Confidence Loss
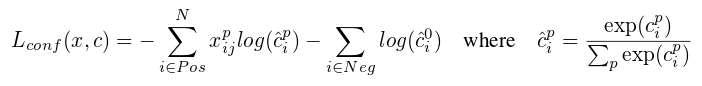
Confidence Loss — formula (3) from the original paper
This is a simple softmax loss function between the actual label and the predicted label. x^p_ij is 1 when there is a matching between the i-th default box and the j-th ground-truth of category p. Note there is a special category corresponding to background boxes (no ground truth is matched). The background boxes are treated as negative, and as we’ll see later, are down-sampled to avoid an highly imbalance training dataset.
Localization Loss
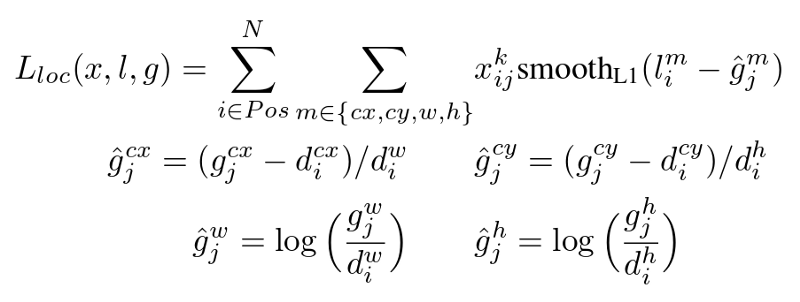
Localization Loss— Formula (2) from the original paper
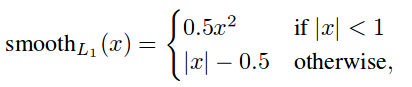
Smooth L1 loss function from Fast R-CNN paper
The localization loss is calculated only on positive boxes (ones with a matched ground truth). It calculates the difference between the correct and predicted offsets to center point coordinates, and the correct and predicted scales to the widths and heights. And smooth the absolute differences.
The differences of offsets and scales are normalized according to the widths and heights of the default boxes, and the scales are log-scaled before taking differences.
The Code
From layers/modules/multibox_loss.py:
def forward(self, predictions, targets):
"""Multibox Loss
Args:
predictions (tuple): A tuple containing loc
preds, conf preds,
and prior boxes from SSD net.
conf shape:
torch.size(batch_size,num_priors,num_classes)
loc shape: torch.size(batch_size,num_priors,4)
priors shape: torch.size(num_priors,4)
ground_truth (tensor): Ground truth boxes and
labels for a batch,
shape: [batch_size,num_objs,5]
(last idx is the label).
"""
loc_data, conf_data, priors = predictions
num = loc_data.size(0)
priors = priors[:loc_data.size(1), :]
num_priors = (priors.size(0))
num_classes = self.num_classes
# match priors (default boxes) and ground truth boxes
loc_t = torch.Tensor(num, num_priors, 4)
conf_t = torch.LongTensor(num, num_priors)
for idx in range(num):
truths = targets[idx][:,:-1].data
labels = targets[idx][:,-1].data
defaults = priors.data
match(self.threshold,truths,defaults,
self.variance,labels,loc_t,conf_t,idx)
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
# wrap targets
loc_t = Variable(loc_t, requires_grad=False)
conf_t = Variable(conf_t,requires_grad=False)
pos = conf_t > 0
num_pos = pos.sum()
# Localization Loss (Smooth L1)
# Shape: [batch,num_priors,4]
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1,4)
loc_t = loc_t[pos_idx].view(-1,4)
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False)
# Compute max conf across batch for hard negative mining
batch_conf = conf_data.view(-1,self.num_classes)
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(
1, conf_t.view(-1,1))
# Hard Negative Mining
loss_c[pos] = 0 # filter out pos boxes for now
loss_c = loss_c.view(num, -1)
_,loss_idx = loss_c.sort(1, descending=True)
_,idx_rank = loss_idx.sort(1)
num_pos = pos.long().sum(1)
num_neg = torch.clamp(
self.negpos_ratio*num_pos, max=pos.size(1)-1)
neg = idx_rank < num_neg.expand_as(idx_rank)
# Confidence Loss Including Positive and Negative Examples
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
conf_p = conf_data[
(pos_idx+neg_idx).gt(0)].view(-1,self.num_classes)
targets_weighted = conf_t[(pos+neg).gt(0)]
loss_c = F.cross_entropy(
conf_p, targets_weighted, size_average=False)
# Sum of losses: L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
N = num_pos.data.sum()
loss_l/=N
loss_c/=N
return loss_l,loss_c
It’s quite long, so let’s break it down:
# match priors (default boxes) and ground truth boxes
loc_t = torch.Tensor(num, num_priors, 4)
conf_t = torch.LongTensor(num, num_priors)
for idx in range(num):
truths = targets[idx][:,:-1].data
labels = targets[idx][:,-1].data
defaults = priors.data
match(self.threshold,truths,defaults,
self.variance,labels,loc_t,conf_t,idx)
# [...]
# wrap targets
loc_t = Variable(loc_t, requires_grad=False)
conf_t = Variable(conf_t,requires_grad=False)
num correspond to the batch size. idx parameter is passed to match() to let match know which row to write.
(Setting requires_grad=False indicates that we do not need to compute gradients with respect to these variables during the backward pass.)[reference]
pos = conf_t > 0
num_pos = pos.sum()
# Localization Loss (Smooth L1)
# Shape: [batch,num_priors,4]
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1,4)
loc_t = loc_t[pos_idx].view(-1,4)
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False)
(Tensor.view is equivalent to numpy.reshape, which returns a new tensor with the same data but different size. Tensor.view_as works the same way, but automatically set the target shape to the shape of the passed tensor.)_
This part calculates the localization loss.
Remember class label 0 correspond to background (negative box), we can use > 0 to find positive boxes.pos is expanded to (num, num_priors, 4) to be used to select the positive boxes. What .view(-1, 4) does is to flatten the tensor from (num, num_priors, 4) to (num * num_priors, 4). F comes from import torch.nn.functional as F.
# Compute max conf across batch for hard negative mining
batch_conf = conf_data.view(-1, self.num_classes)
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(
1, conf_t.view(-1,1))
# Hard Negative Mining
loss_c[pos] = 0 # filter out pos boxes for now
loss_c = loss_c.view(num, -1)
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
num_pos = pos.long().sum(1)
num_neg = torch.clamp(
self.negpos_ratio * num_pos, max=pos.size(1)-1)
neg = idx_rank < num_neg.expand_as(idx_rank)
(Tensor.gather gathers values along an axis specified by dim.)
(Tensor.sort is similar to Tensor.min and Tensor.max. It returns two tensors: 1. sorted values. 2. original index of the sorted value)
For confidence loss SSD use a technique called hard negative mining, that is, select the most difficult negative boxes (they have higher confidence loss) so negative to positive ratio is at most 3:1.
log_sum_exp comes from layers/box_utils.py. It computes the denominator part of log(c). batch_conf.gather computes the numerator part, where only the predicted probability to the true label matters.
The code use two sort to find the rank of each box. Firstly get the sorted index, then get the sorted index of sorted index as the rank. The num_neg is clamped by num_priors — 1 , which seems weird. The actual number of negative num_prior — num_pos seems more reasonable.
# Confidence Loss Including Positive and Negative Examples
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
conf_p = conf_data[
(pos_idx+neg_idx).gt(0)].view(-1,self.num_classes)
targets_weighted = conf_t[(pos+neg).gt(0)]
loss_c = F.cross_entropy(
conf_p, targets_weighted, size_average=False)
This is part should be pretty straight forward. Collect the predictions and true labels, and then pass to cross_entropy function to get the overall loss (not averaged yet).
# Sum of losses: L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
N = num_pos.data.sum()
loss_l /= N
loss_c /= N
return loss_l, loss_c
Finally, average both losses and return them. Now we have everything we need to train the network.
Inference
After training the network, it’s time to put our detector to use. One particular problem from SSD design is that we can match multiple default boxes to a single ground truth box if the threshold is passed. Therefore when predicting we might predict multiple highly-overlapped boxes around an object. This is normally not the desired output of a object detection algorithm. We need to do a bit of post-processing.
The technique SSD use is called non-maximum suppression (nms). The basic idea is to iteratively add most confident boxes to the final output. If a candidate box highly overlaps (has a Jaccard overlap higher than 0.45) any box of the same class from the final output, the box is ignored. It also caps the total predicted boxes at 200 per image.
The implementation (nms function) is located at layers/box_utils.py. It has some new things like Tensor.numel and torch.index_select with out parameter. But you should be quite familiar with the work flow by now, so I won’t analyze the code in detail here.
Thank You
That’s it! Thank you very much for read through the entire series. I haven’t written such long learning note / tutorial for a while, and it feels great to do it again!
The purpose of this series is really to force myself to drill into the messy details and understand what’s going on. I’d be glad if it helps you in any way. Also please feel free to let me know if I got something wrong or missed something important.