Introduction
Today we’re examining this very interesting and alarming paper in the field of recommender systems — Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches. It also has an extended version still under review — A Troubling Analysis of Reproducibility and Progress in Recommender Systems Research.
The first author of the papers also gave an overview and answered some questions to the first paper in this YouTube video (he also mentioned some of the contents in the extended version, e.g., the information leakage problem):
Key Points
Identified Problems
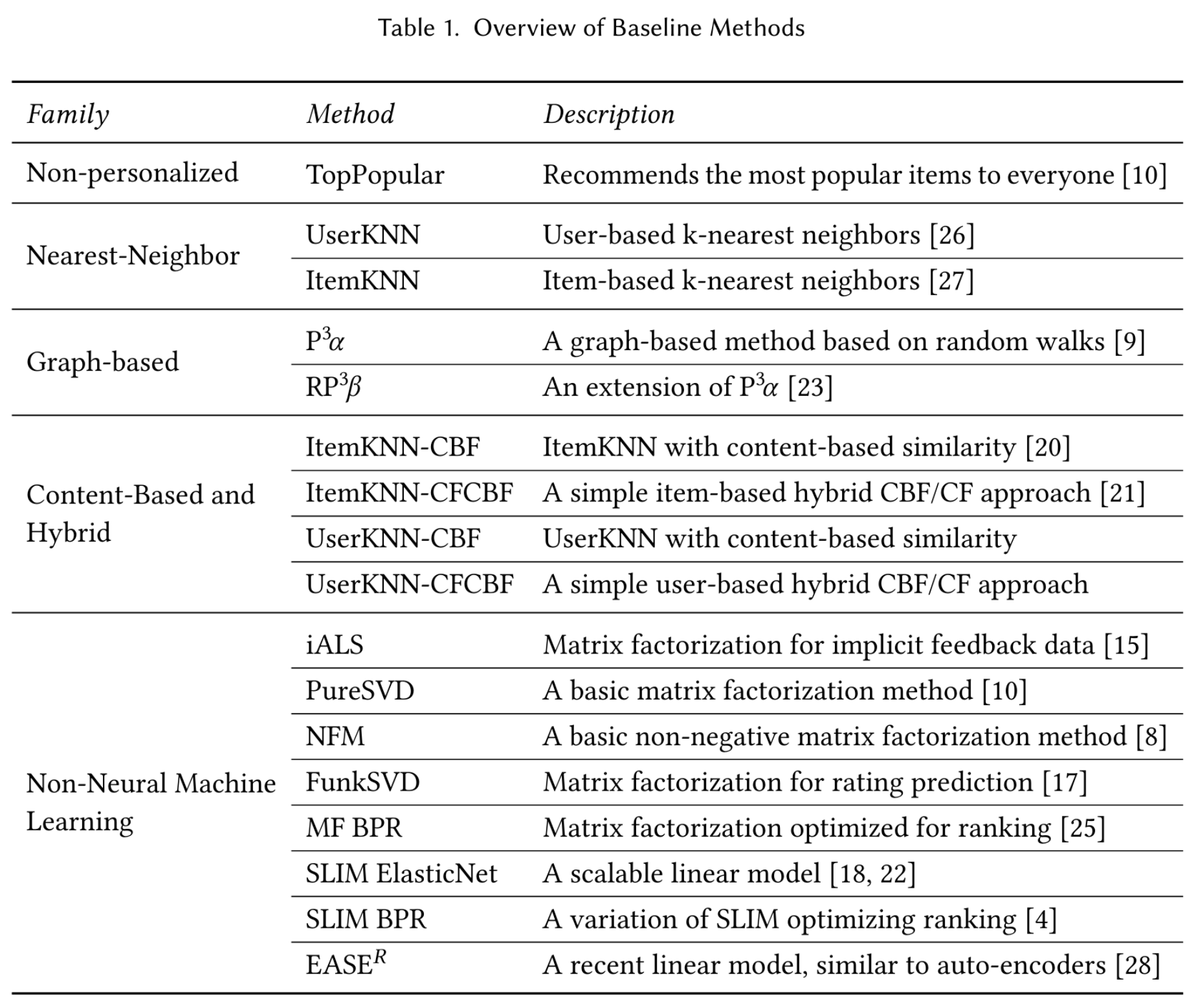
- Reproducibility: less than half of the top papers (7/18 in the original paper, 12/26 in the extended version) in this field can be reproduced.
- Progress: only 1/7 (in the original paper) of the results can be shown to outperform well-tuned baselines consistently.
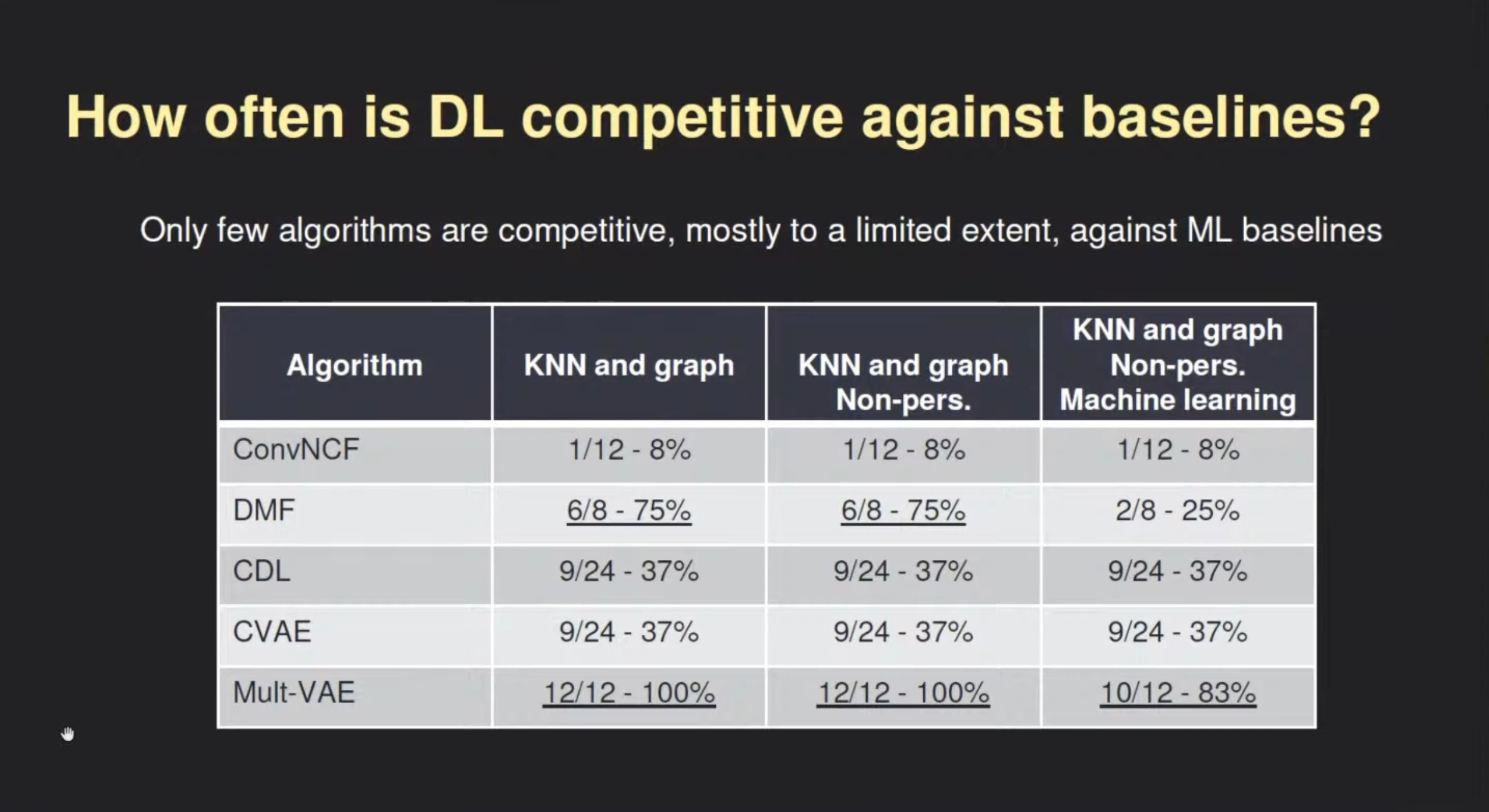
The extended paper also raised some issues that make measuring the progress of the field harder:
- Arbitrary experimental design: the choices of the evaluation procedures are not well justified.
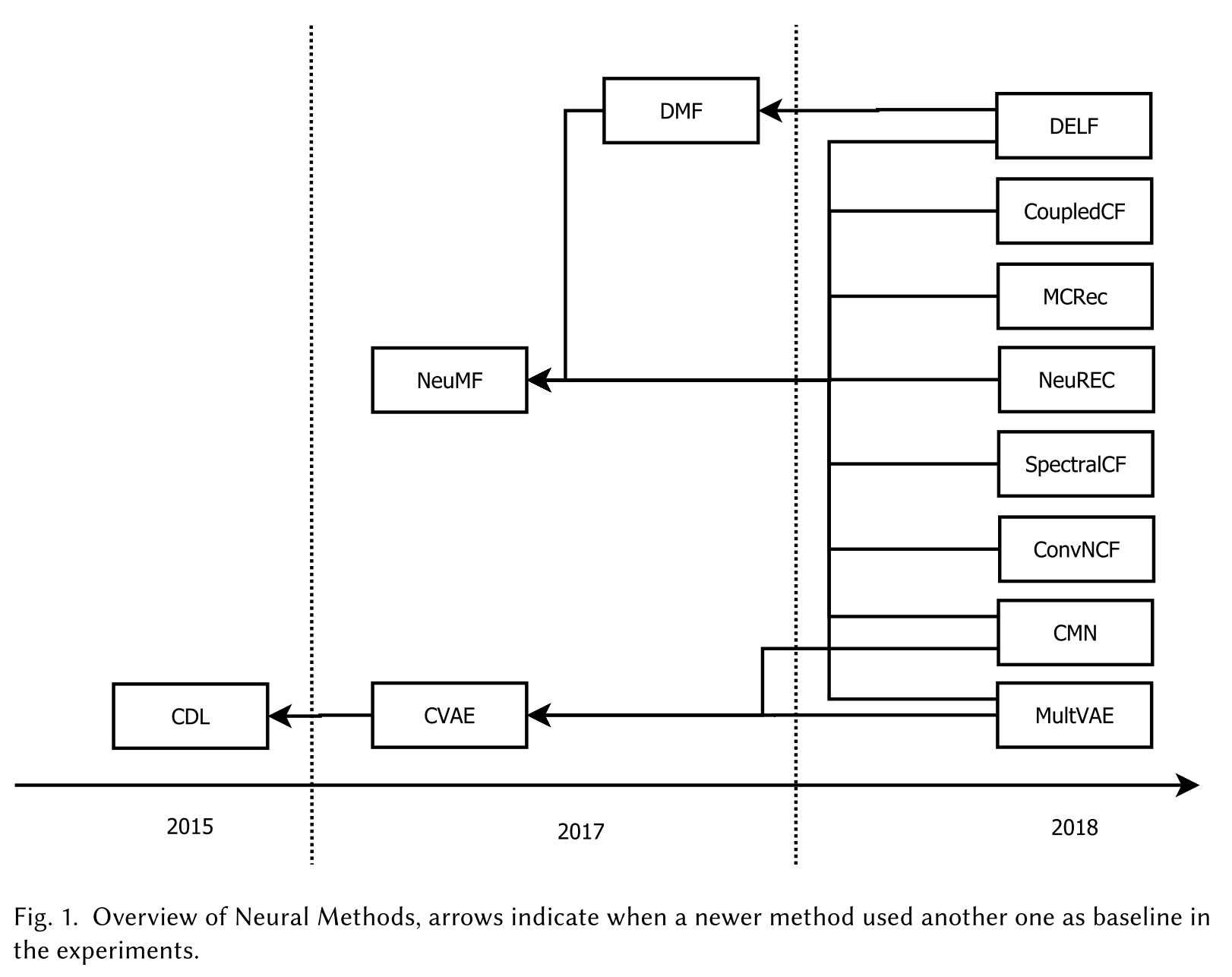
- Selection and propagation of weak baselines: as some of the top papers started to use only weaker baselines, the newer papers tend to keep using only those baselines, thus polluting the entire line of research.
- Errors and information leakage: besides mistakes in code, some of the paper committed one of the cardinal sins in ML — use the test set to do hyper-parameter tuning.
Implications for Practitioners
- Don’t go with the fancy deep learning algorithm on the first try. It could cost you valuable time as the complexity of modern deep learning algorithms are often relatively high and still give you sub-optimal performance.
- Instead, start by examining your dataset and fine-tuning applicable baseline models. If your dataset is highly unbalanced, personalized recommendations could be worse than simply recommending the most popular items.
- Remember, the receivers of the recommendations are actual humans. The metric you choose does not necessarily reflect the users’ preference. Make sure improvement in your selected metric can translate to higher user satisfaction is your top priority.
As a Guide to the Field
The author of the paper published the code on Github, which, combined with the paper, can be a great learning resource for practitioners. However, bear in mind that this paper only covers the top-n recommendation task. You might also need to find specialized models for other tasks.