
Introduction
Recently I came across the article “How to Generate Synthetic Data? — A synthetic data generation dedicated repository”. The post introduces Wasserstein GAN[1] and demonstrates how to use it to generate synthetic(fake) data that looks very “real” (i.e., has similar statistical properties as the real data). This topic interests me as I’ve been wondering if we can reliably generate augmented data for tabular data. The author open-sourced the code on Github, so I decided to take some time to reproduce the results, make some improvements, and check if the quality of the synthetic data is good enough to use to augment the data or even replace the training data.
Some Contexts
It’s well known that in computer vision, we can slightly tweak the image to create more training data(check my post on this topic). And we are starting to see some promising results in the field of NLP (check my post about a recent paper by NVIDIA that trains QA models from synthetic data[2]).
On the other hand, although already prevalent in the digital world(e.g., online advertisement CTR prediction), tabular data does not seem to have an established way to generate augmented data yet, as far as I know. There isn’t much research or breakthrough on it in the latest deep learning boom, either.
Synthetic Data
According to the Github repo, synthetic data can be used for these applications:
- Privacy
- Remove bias
- Balance datasets
- Augment datasets
Augmentation is an obvious one. We can also increase the number of training data in the minority classes to balance the dataset. I’m not sure about removing bias. Maybe it’s done via adding data to underrepresented groups.
We can expect the privacy infringement can be reduced by using synthetic data, but by how much? I’m not familiar with privacy protection enough to judge. My guess is that it depends. For example, if the data contains the GPS coordinates of my home, the synthetic data might contain a row that looks notably like mine, with the coordinates slightly off (e.g., by 100 meters). In this case, any one of the hundreds of people in my neighborhood can be a suspected source of that row; therefore, my privacy is preserved. However, if it is known that I’m the only one using the service in the vicinity, then this protection becomes meaningless.
In this post, we’re going to try:
- Augment the dataset to see if we can to get better accuracy.
- Replace part of the dataset with synthetic data (to preserve the privacy potentially).
The Experiment
Modifications to the Original Code
I’ve fixed some minor bugs in the code (PR submitted) and added a notebook containing the experiment used in this post. The code can be found at ceshine/ydata-synthetic (tag blog-post-20201214).
I’ve made some changes to the original GAN example notebook:
- No use of cluster label in the GAN training: I don’t see any benefits in adding this feature.
- Removed the K-mean clustering on fraud data: as stated above, it doesn’t do anything other than making the plot a bit prettier.
- Use Wasserstein GAN with gradient penalty[3] instead of vanilla GAN.
- Change the batch size and epoch number.
- Removed some redundant code.
- Load data from Google Drive (this is for Google Colab only. You need to upload the data to your Google Drive folder.)
- Use
%watermarkto record the package version.
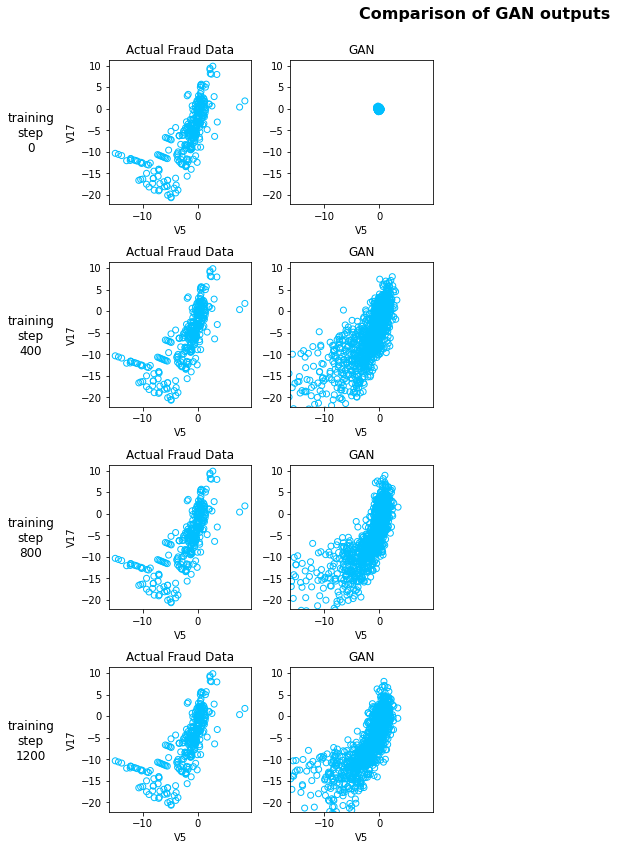
Real v.s. Fake (WGAN-GP)
Experiment Setup
- Following the original notebook, we only generate fraud data (class = 1), which only has 492 rows.
- We perform a 60-20-20 train-valid-test split on these rows.
- GAN is trained only on the training set (295 rows) to avoid information leaks.
- 20,000 negative rows (class = 0) are randomly sampled (out of 284,315). The same 60-20-20 split are also applied.
- Classification thresholds are decided by the F1 score on the validation set and are carried to the test set.
(Note that the number of positive cases is small that the evaluation results might not be reliable.)
We fit random forest models with the same hyper-parameters (max_depth=8, max_leaf_node=64, class_weight=balance_subsample) on these three scenarios:
- Real Only - Train on the 12,000 real negative rows + 295 real positive rows
- Real + Fake - Train on the 12,000 real rows + 295 real positive rows + 960 synthetic rows
- Fake - Train on the 12,000 real rows + 960 synthetic rows
Results

- We cannot see visible improvement by augmenting the dataset with synthetic data.
- We get close-to-real performance when trained with only fake positive data.
Code
Here’s the link to the notebook. You can also open it on Google Colab:
![]()
Conclusion
Although the augmentation approach did not bring better accuracies, it did not make it worse, either. This means the generated positive data was not confused by the model with the real negative data. It resides on the right side of the decision boundary.
The all-fake scenario works unexpectedly well. I probably should have expected it from what I just said about the augmented case. From the visualization of the generated data, we can see that the GAN model did not merely reproduce the training data, so it can potentially provide some form of obfuscation of personal information (again, I’m not sure by how much).
The results are promising. Some future research direction:
- Generate negative data, too(arguably, the privacy of the people who did not commit fraud should be prioritized over one of those who did).
- Find a dataset on which the augmentation approach brings better results.
- Dealing with categorical data. Treating them as continuous is an obvious solution, but I think there should be better ways.
- Measure the similarity between the generated data and the real data (to measure the level of privacy preserved). The discriminator or critic in the GAN model already does this on some level, but we might need a better metric.
- Maybe Auto-encoders would work as well?
References
- Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein GAN.
- Puri, R., Spring, R., Patwary, M., Shoeybi, M., & Catanzaro, B. (2020). Training Question Answering Models From Synthetic Data.
- Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., & Courville, A. (2017). Improved Training of Wasserstein GANs.